目次
タイムテーブル
- PDFはこちら
にあります.
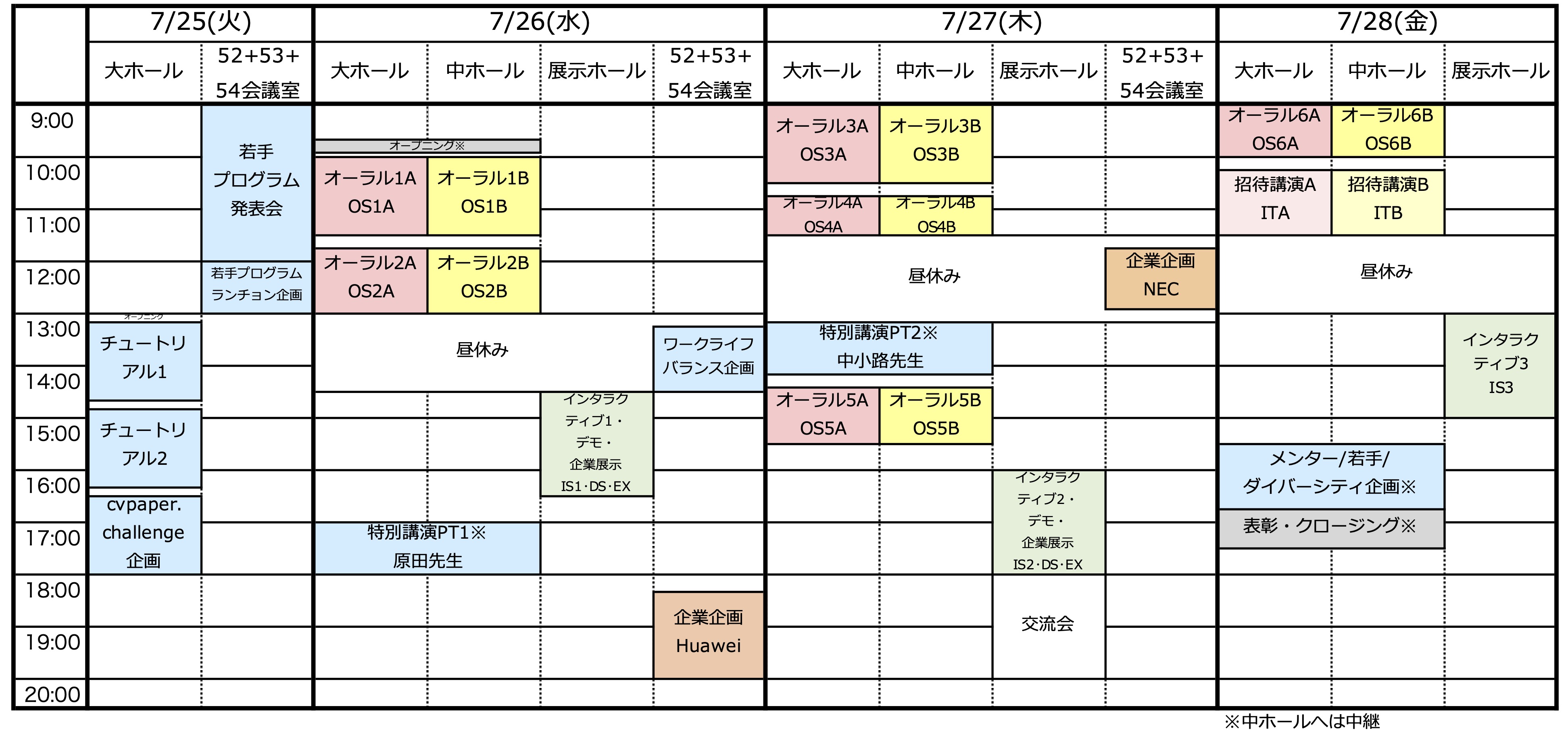
7月25日(火)
9:00-12:00 若手プログラム発表会 (会場:52+53+54会議室)
12:00-13:00 若手プログラムランチョン企画 (会場:52+53+54会議室)
- 若手プログラム発表会およびランチョン企画については,若手プログラム参加者限定とさせていただきます.映像中継等もございません.
13:00-13:10 MIRUチュートリアル x CCC Summer 2023 オープニング (会場:大ホール) (座長:井上中順,片岡裕雄)
13:10-14:40 TT1: チュートリアル1 (会場:大ホール) (座長:井上中順)
14:40-14:50 休憩
14:50-16:20 TT2: チュートリアル2 (会場:大ホール) (座長:井上中順)
16:20-16:30 休憩
16:30-18:00 cvpaper.challenge企画 (会場:大ホール) (座長:片岡裕雄)
7月26日(水)
9:40-9:50 オープニング (会場:大ホール,中ホール(中継)) (座長:浦西友樹)
9:50-10:00 移動
10:00-11:30 OS1A: オーラル1A(画像生成/変換) (会場:大ホール) (座長:金子卓弘,橋本敦史)
都合により,OS1A-S1とOS1A-S6の発表順を入れ替えました.
- OS1A-L1:本部勇真, 山口廉斗, 柳井啓司 (電通大),StableSeg: Stable Diffusionによるゼロショット領域分割
- OS1A-L2:吉橋亮太, 大塚雄也, 土井賢治, 田中智大 (ヤフー),アテンションはアノテーションの代わりになるか?:テキスト−画像生成モデルの注意機構を利用した領域分割の弱教師あり学習
- OS1A-L3:塩原楓, 小杉哲, 山崎俊彦 (東大),単一ステージモデルによる遮蔽物を考慮した顔交換
- OS1A-S6:塩原楓 (東大), 楊興超, 武富貴史 (サイバーエージェント),顔交換のためのアイデンティティエンコーダの再考
- OS1A-S2:塙剛生, 河合洋弥, 伊藤康一, 青木孝文 (東北大),プライバシ保護のための特徴量埋め込みに基づく顔画像の非識別化とその性能評価
- OS1A-S3:Gido Kato, Yoshihiro Fukuhara (Waseda Univ.), Mariko Isogawa (Keio Univ.), Hideki Tsunashima (Waseda Univ.), Hirokatsu Kataoka (AIST), Shigeo Morishima (Waseda Research Institute for Science and Engineering),Scapegoat Generation for Privacy Protection from Malicious Deepfake
- OS1A-S4:梶凌太, 柳井啓司 (電通大),VQ-VDM: ベクトル量子化変分オートエンコーダと 拡散モデルを用いた動画生成モデル
- OS1A-S5:西川潤, 石井雅人 (ソニーグループ),時刻毎に異なる計算量のネットワークを用いた拡散確率モデルの推論高速化
- OS1A-S1:磯部凌, 川上玲 (東工大), 佐藤育郎 (東工大, デンソーITラボ),回帰器と生成器の協調による視線角度推論
- OS1A-S7:岸部真紀, 和田俊和 (和歌山大),人物再同定のための遮蔽物による色移りを抑えた人物画像の姿勢変換
10:00-11:30 OS1B: オーラル1B(学習方法・教師無し/弱教師付/ゼロショット/転移学習) (会場:中ホール) (座長:佐藤育郎,関川雄介)
- OS1B-L1:村本佳隆, 岡本直樹, 平川翼, 山下隆義, 藤吉弘亘 (中部大),知識転移グラフによる最適な半教師あり共同学習の探索
- OS1B-L2:松尾信之介 (九大), 末廣大貴 (九大, 理研), 内田誠一 (九大), 伊藤寛朗, 寺田和弘, 吉澤明彦 (京大), 備瀬竜馬 (九大),WSIに対する部分的なラベル比率からの学習
- OS1B-S1:Guang Li, Ren Togo, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Dataset Distillation via Self-Adaptive Parameter Matching
- OS1B-S2:Kazuki Egashira, Atsuyuki Miyai, Qing Yu (Univ. of Tokyo), Go Irie (Tokyo Univ. of Science), Kiyoharu Aizawa (Univ. of Tokyo),Preventing Undesirable Misclassification by Negative Learning
- OS1B-S3:Chun Yang Tan, Kazuhiko Kawamoto, Hiroshi Kera (Chiba Univ.),Exploiting Frequency Spectrum of Adversarial Images for General Robustness
- OS1B-S4:Atsuyuki Miyai, Qing Yu (Univ. of Tokyo), Go Irie (Tokyo Univ. of Science), Kiyoharu Aizawa (Univ. of Tokyo),CLIP-based Zero-Shot In-Distribution Detection
- OS1B-S5:古田諒佑, 佐藤洋一 (東大),物体検出の半教師有りおよび弱教師有りドメイン汎化
- OS1B-S6:山上駿也 (東京理科大), 郁青, 相澤清晴 (東大), 入江豪 (東京理科大),Random Pseudo Labelingによる教師なしドメイン推定
- OS1B-S7:大内竜馬, 吉田周平, 寺尾真, 宮川大輝, 柴田剛志 (NEC), 岡谷貴之 (東北大, 理研), 杉山将 (理研, 東大),時系列行動区間認識のアノテーションコストを削減する飛ばし見型弱ラベル学習法
- OS1B-S8:Yasufumi Kawano, Yoshiki Nagasaki (Keio Univ., AIST), Kensho Hara (AIST), Yoshimitsu Aoki (Keio Univ.), Hirokatsu Kataoka (AIST),Unsupervised Semantic Segmentation Leveraging Video Consistency
- OS1B-S9:Zongyao Li, Ren Togo, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Source-data-free Domain-adaptive Semantic Segmentation with Inter-domain and Intra-domain Style Transfer
11:30-11:45 休憩
11:45-13:00 OS2A: オーラル2A(3次元解析・反射解析) (会場:大ホール) (座長:田中賢一郎,佐川立昌)
- OS2A-L1:Ryota Maeda (Univ. of Hyogo), Kenshi Takayama, Takafumi Taketomi (CyberAgent),Refinement of Hair Geometry by Strand Integration
- OS2A-L2:大森涼平, 川原僚, 岡部孝弘 (九工大),周波数解析に基づく少数画像からの表面粗さ推定
- OS2A-L3:松本侑也, 中野学, 小倉一峰 (NEC),点対応と線分対応を用いたIndoor visual localization
- OS2A-L4:芦田光平, 山藤浩明, 大倉史生, 松下康之 (阪大),Dual Pixelセンサを用いたStructure from Motionのスケール推定
- OS2A-S1:小林茂樹 (筑波大, AIST), 佐々木洋子, 櫻田健, 濱口竜平, 大西正輝 (AIST), 伊達央, 大矢晃久 (筑波大),三次元点群地図に対する単眼カメラの姿勢推定を目的とした密なクロスモーダルマッチング
- OS2A-S2:舩冨卓哉 (NAIST, JSTさきがけ), 山田重人, 宇都宮夏子 (京大), 藤村友貴, 櫛田貴弘, 向川康博 (NAIST),非剛体位置合わせの全体最適化による連続組織切片からの3次元復元
11:45-13:00 OS2B: オーラル2B(異常検知・車載/ロボットビジョン・医用画像処理) (会場:中ホール) (座長:櫻田健,佐藤育郎)
- OS2B-L1:岩崎幸生, 石原賢太,井下哲夫 (NEC),コンパクト多様体を備えたオートエンコーダによる動画異常検知
- OS2B-S1:枌尚弥, 大山博之, 柴田剛志, 寺尾真 (NEC),長期の未来予測を用いたロボット制御計画の成否識別
- OS2B-S2:牧原昂志 (阪大, AIST), 山田亮佑 (筑波大, AIST), 堂前幸康, 片岡裕雄 (AIST), 原田研介 (阪大, AIST),数式ドリブン教師あり学習を用いた把持位置検出
- OS2B-S3:小田桐和也, 小野口一則 (弘前大),Occupancy Grid Mappingによる単眼死角推定
- OS2B-S4:丸山裕太, 大橋剛介 (静岡大),車載カメラ画像における視覚的注意と FOEの乖離度を用いた事故予測モデル
- OS2B-S5:Chenkai Zhang, Daisuke Deguchi, Hiroshi Murase (Nagoya Univ.),Explainability Enhancement module for End-to-End Driving Models by Focusing on the important objects
- OS2B-S6:奥尾拓己, 西村和也 (九大), 伊藤寛朗, 寺田和弘, 吉澤明彦 (京大), 備瀬竜馬 (九大),Learning from Label Proportionによる陽性腫瘍の比率推定
- OS2B-S7:西村和也 (九大), 刀谷在美, 中馬新一郎 (京大), 備瀬竜馬 (九大),時間順序反転を用いたデータセット作成による 部分的なアノテーションによる細胞分裂検出
- OS2B-S8:都築幸乃, 吉田龍人, 大久保順一, 藤井純一郎 (八千代エンジニヤリング), 山下隆義 (中部大),異常検知のためのSQ-VAEコードブックへのアプローチ
- OS2B-S9:中世古真吾, 高橋隆史 (龍谷大),CNNから抽出した画像特徴量の線形回帰に基づく画像の異常検出
13:00-14:30 昼休憩
13:15-14:30 ワークライフバランス企画 (会場:52+53+54会議室) (座長:内海ゆづ子)
14:30-16:30 IS1: インタラクティブ1 (会場:展示ホール)
- OS1A-L1:本部勇真, 山口廉斗, 柳井啓司 (電通大),StableSeg: Stable Diffusionによるゼロショット領域分割
- OS1A-L2:吉橋亮太, 大塚雄也, 土井賢治, 田中智大 (ヤフー),アテンションはアノテーションの代わりになるか?:テキスト−画像生成モデルの注意機構を利用した領域分割の弱教師あり学習
- OS1A-L3:塩原楓, 小杉哲, 山崎俊彦 (東大),単一ステージモデルによる遮蔽物を考慮した顔交換
- OS1A-S1:磯部凌, 川上玲 (東工大), 佐藤育郎 (東工大, デンソーITラボ),回帰器と生成器の協調による視線角度推論
- OS1A-S2:塙剛生, 河合洋弥, 伊藤康一, 青木孝文 (東北大),プライバシ保護のための特徴量埋め込みに基づく顔画像の非識別化とその性能評価
- OS1A-S3:Gido Kato, Yoshihiro Fukuhara (Waseda Univ.), Mariko Isogawa (Keio Univ.), Hideki Tsunashima (Waseda Univ.), Hirokatsu Kataoka (AIST), Shigeo Morishima (Waseda Research Institute for Science and Engineering),Scapegoat Generation for Privacy Protection from Malicious Deepfake
- OS1A-S4:梶凌太, 柳井啓司 (電通大),VQ-VDM: ベクトル量子化変分オートエンコーダと 拡散モデルを用いた動画生成モデル
- OS1A-S5:西川潤, 石井雅人 (ソニーグループ),時刻毎に異なる計算量のネットワークを用いた拡散確率モデルの推論高速化
- OS1A-S7:岸部真紀, 和田俊和 (和歌山大),人物再同定のための遮蔽物による色移りを抑えた人物画像の姿勢変換
- OS1B-L1:村本佳隆, 岡本直樹, 平川翼, 山下隆義, 藤吉弘亘 (中部大),知識転移グラフによる最適な半教師あり共同学習の探索
- OS1B-L2:松尾信之介 (九大), 末廣大貴 (九大, 理研), 内田誠一 (九大), 伊藤寛朗, 寺田和弘, 吉澤明彦 (京大), 備瀬竜馬 (九大),WSIに対する部分的なラベル比率からの学習
- OS1B-S1:Guang Li, Ren Togo, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Dataset Distillation via Self-Adaptive Parameter Matching
- OS1B-S2:Kazuki Egashira, Atsuyuki Miyai, Qing Yu (Univ. of Tokyo), Go Irie (Tokyo Univ. of Science), Kiyoharu Aizawa (Univ. of Tokyo),Preventing Undesirable Misclassification by Negative Learning
- OS1B-S3:Chun Yang Tan, Kazuhiko Kawamoto, Hiroshi Kera (Chiba Univ.),Exploiting Frequency Spectrum of Adversarial Images for General Robustness
- OS1B-S4:Atsuyuki Miyai, Qing Yu (Univ. of Tokyo), Go Irie (Tokyo Univ. of Science), Kiyoharu Aizawa (Univ. of Tokyo),CLIP-based Zero-Shot In-Distribution Detection
- OS1B-S5:古田諒佑, 佐藤洋一 (東大),物体検出の半教師有りおよび弱教師有りドメイン汎化
- OS1B-S6:山上駿也 (東京理科大), 郁青, 相澤清晴 (東大), 入江豪 (東京理科大),Random Pseudo Labelingによる教師なしドメイン推定
- OS1B-S7:大内竜馬, 吉田周平, 寺尾真, 宮川大輝, 柴田剛志 (NEC), 岡谷貴之 (東北大, 理研), 杉山将 (理研, 東大),時系列行動区間認識のアノテーションコストを削減する飛ばし見型弱ラベル学習法
- OS1B-S8:Yasufumi Kawano, Yoshiki Nagasaki (Keio Univ., AIST), Kensho Hara (AIST), Yoshimitsu Aoki (Keio Univ.), Hirokatsu Kataoka (AIST),Unsupervised Semantic Segmentation Leveraging Video Consistency
- OS1B-S9:Zongyao Li, Ren Togo, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Source-data-free Domain-adaptive Semantic Segmentation with Inter-domain and Intra-domain Style Transfer
- OS2A-L1:Ryota Maeda (Univ. of Hyogo), Kenshi Takayama, Takafumi Taketomi (CyberAgent),Refinement of Hair Geometry by Strand Integration
- OS2A-L2:大森涼平, 川原僚, 岡部孝弘 (九工大),周波数解析に基づく少数画像からの表面粗さ推定
- OS2A-L3:松本侑也, 中野学, 小倉一峰 (NEC),点対応と線分対応を用いたIndoor visual localization
- OS2A-L4:芦田光平, 山藤浩明, 大倉史生, 松下康之 (阪大),Dual Pixelセンサを用いたStructure from Motionのスケール推定
- OS2A-S1:小林茂樹 (筑波大, AIST), 佐々木洋子, 櫻田健, 濱口竜平, 大西正輝 (AIST), 伊達央, 大矢晃久 (筑波大),三次元点群地図に対する単眼カメラの姿勢推定を目的とした密なクロスモーダルマッチング
- OS2A-S2:舩冨卓哉 (NAIST, JSTさきがけ), 山田重人, 宇都宮夏子 (京大), 藤村友貴, 櫛田貴弘, 向川康博 (NAIST),非剛体位置合わせの全体最適化による連続組織切片からの3次元復元
- OS2B-L1:岩崎幸生, 石原賢太,井下哲夫 (NEC),コンパクト多様体を備えたオートエンコーダによる動画異常検知
- OS2B-S1:枌尚弥, 大山博之, 柴田剛志, 寺尾真 (NEC),長期の未来予測を用いたロボット制御計画の成否識別
- OS2B-S2:牧原昂志 (阪大, AIST), 山田亮佑 (筑波大, AIST), 堂前幸康, 片岡裕雄 (AIST), 原田研介 (阪大, AIST),数式ドリブン教師あり学習を用いた把持位置検出
- OS2B-S3:小田桐和也, 小野口一則 (弘前大),Occupancy Grid Mappingによる単眼死角推定
- OS2B-S4:丸山裕太, 大橋剛介 (静岡大),車載カメラ画像における視覚的注意と FOEの乖離度を用いた事故予測モデル
- OS2B-S5:Chenkai Zhang, Daisuke Deguchi, Hiroshi Murase (Nagoya Univ.),Explainability Enhancement module for End-to-End Driving Models by Focusing on the important objects
- OS2B-S6:奥尾拓己, 西村和也 (九大), 伊藤寛朗, 寺田和弘, 吉澤明彦 (京大), 備瀬竜馬 (九大),Learning from Label Proportionによる陽性腫瘍の比率推定
- OS2B-S7:西村和也 (九大), 刀谷在美, 中馬新一郎 (京大), 備瀬竜馬 (九大),時間順序反転を用いたデータセット作成による 部分的なアノテーションによる細胞分裂検出
- OS2B-S8:都築幸乃, 吉田龍人, 大久保順一, 藤井純一郎 (八千代エンジニヤリング), 山下隆義 (中部大),異常検知のためのSQ-VAEコードブックへのアプローチ
- OS2B-S9:中世古真吾, 高橋隆史 (龍谷大),CNNから抽出した画像特徴量の線形回帰に基づく画像の異常検出
- IS1-1:河内穂高, 中村友哉 (阪大), 岩田和也 (阪大, 京大), 槇原靖, 八木康史 (阪大),回折格子を用いたスナップショット空間超解像ToFイメージングデバイス
- IS1-2:奥野広之, 都竹千尋, 高橋桂太, 藤井俊彰 (名大),イベント情報を用いた動画像の高フレームレート化における座標ベースニューラル表現の活用
- IS1-3:蛭子綾花 (筑波大), 青砥隆仁 (Optech Innovation), 北野和哉 (NAIST), 髙谷剛志 (筑波大),偏光変調を用いた相関演算による間接Time-of-Flight法の検討
- IS1-4:矢野海結 (千葉大), 岩口尭史, 川崎洋 (九大), 久保尋之 (千葉大),分光カメラのスキャンラインと平行な照明ラインの距離に応じた表面下散乱光の選択的な獲得
- IS1-5:櫛田貴弘 (立命館大, NAIST), 藤村友貴, 舩冨卓哉, 向川康博 (NAIST),物理ベース微分可能レンダリングによるTime-of-Flightカメラの計測誤差の低減
- IS1-6:大野愛語, 坂上文彦, 佐藤淳 (名工大),高周波偏光投影を用いた散乱媒体画像の解析
- IS1-7:Junkei Okada, Yuko Ozasa (Tokyo Denki Univ.),Evaluation of Deep Feature Reconstruction for Hyperspectral Pixel-wise Classification
- IS1-8:中野汰一, 田中正行, 奥富正敏 (東工大),勾配領域処理に基づくノイズを考慮した遠赤外線画像の可視化
- IS1-9:安藤友美, 坂上文彦, 佐藤淳 (名工大),運動動画像からの時刻ごとの人物姿勢と詳細形状の同時推定
- IS1-10:Qi Feng (Waseda Univ.), Hubert P. H. Shum (Durham Univ.), Shigeo Morishima (Waseda Research Institute for Science and Engineering),Learning Omnidirectional Depth Estimation from Internet Videos
- IS1-11:Wenbin Luo, Takafumi Iwaguchi (Kyushu Univ.), Hajime Nagahara (Osaka Univ.), Ryusuke Sagawa (AIST), Hiroshi Kawasaki (Kyushu Univ.),Pseudo Random Modulation on Base-modulation of I-ToF to Avoid Multi-ToF Interference
- IS1-12:Takayuki Shinohara, Li YongHe, Mitsuteru Sakamoto, Toshiaki Satoh (PASCO),3D building modeling method combining point cloud instance segmentation and signed distance functions
- IS1-13:Xuanmeng Sha, Tomohiro Mashita (Osaka Univ.),Momentum Contrastive Learning for 3D Local Features
- IS1-14:浦川雄気, 渡辺義浩 (東工大),振幅変化補正を用いた高速な位相シフト法
- IS1-15:熊谷はるか, 山下陸, 松井勇佑 (東大),NeRFにおける陰影付けレンダリング
- IS1-16:池田貴希, 木原優輝, Tang Yi (九大), 佐藤啓宏 (京都先端科学大), 岩口尭史, Diego Thomas, 川崎洋 (九大),複数の十字平面レーザとDVLを組み合わせた 広域水中SLAMにおける姿勢最適化手法
- IS1-17:Hanwei Zhang (Kyushu Univ.), Hideaki Uchiyama (NAIST), Shintaro Ono (Fukuoka Univ.), Hiroshi Kawasaki (Kyushu Univ.),Dynamic Neural Scene Representation for Urban Scenes with 2D Panoptic Priors
- IS1-18:石川航太郎 (九大), 長枝浩 (ノア), Diego Thomas, 川崎洋 (九大),動画像からの動物フィギュア作成のためのニューラル表現に深度データを用いた3次元モデル生成手法
- IS1-19:武田司, 山口周悟, 佐藤和仁, 深澤康介 (早大), 森島繁生 (早大理工学術院総合研究所),NeRFの効率的な三次元再構成のためのカメラポーズ補間手法の提案
- IS1-20:古川亮 (近大), 佐川立昌 (AIST), 川崎洋 (九大),能動ステレオ法における形状及びパラメータ推定のためのボリュームレンダリング法
- IS1-21:後藤潤平, 中田洋平, 安倍清史, 石井育規 (パナソニックホールディングス), 山下隆義 (中部大),正規直交行列によるクラス内の多峰性を考慮したクラス分類
- IS1-22:三宮隆寛, 堀田一弘 (名城大),二つのネットワークの差を用いた判断根拠の可視化
- IS1-23:森田耀仁, 奥野弘嗣 (阪工大),生体視覚神経系に学んだ前処理を用いたCNNによる画像識別
- IS1-24:新谷知大, 鈴木昌人, 高橋智一, 新井泰彦, 前泰志, 青柳誠司 (関西大),コサイン類似度による物体概念の生成と人間の認識モデルを模倣した画像認識器の開発
- IS1-25:倉見泰至 (名城大), 石川卓哉 (名大), 堀田一弘 (名城大),膵臓疾患における超音波内視鏡下穿刺吸引組織の識別のためのDeformableFormer
- IS1-26:加藤聡太, 堀田一弘 (名城大),クラス不均衡な画像分類に対するLarge Marginに基づいた新たな損失関数の提案
- IS1-27:加太将弘, 吉橋亮太, 川上玲 (東工大), 池畑諭 (東工大, NII), 佐藤育郎 (東工大, デンソーITラボ),対照学習に基づく Mixture of Experts の経路表現学習
- IS1-28:Jinrong Liang (Tokyo Institute of Technology), Shinya Gongyo, Mitsuru Ambai (Denso IT Lab.), Rei Kawakami (Tokyo Institute of Technology), Ikuro Sato (Tokyo Institute of Technology, Denso IT Lab.),Learning Non-Uniform Step-Sizes for Neural Network Quantization
- IS1-29:若山浩之, 平川翼, 山下隆義, 藤吉弘亘 (中部大),CNNとViTを組み合わせたモデルのノイズへの頑健性
- IS1-30:鳥羽真仁, 内田誠一 (九大), 早志英朗 (阪大),Energy-based modelを用いた信頼度較正と疑似ラベル学習への応用
- IS1-31:田中勇貴, 寺尾真, 柴田剛志 (NEC), 岡谷貴之 (理研, 東北大), 杉山将 (理研, 東大),撮影角度変化に頑健な姿勢間距離に基づく画像分類向けカリキュラム半教師あり学習
- IS1-32:松本悠希, 三浦勝司 (住友電工), 奥野拓也 (住電通信エンジニアリング), 尾澤知憲 (ユニコ), 藤吉弘亘 (中部大),SimCLR にABNを導入することによる注視領域の可視化および精度向上の試み
- IS1-33:東本良太, 吉田壮, 棟安実治 (関西大),弱教師あり学習のための混合データ拡張手法
- IS1-34:石堂柚希, 柴田千尋 (法政大),自己教師あり学習における局所的な表現の獲得に対する評価手法の検討
- IS1-35:平本麗弥, 前田英作 (東京電機大),事前学習データの違いにおけるモデル盗用に対する防御性能の影響について
- IS1-36:Satoshi Kondo (Muroran Institute of Technology),Black-Box Unsupervised Domain Adaptation for Medical Image Segmentation
- IS1-37:土井田啓輔, 堀田一弘 (名城大),特徴量の分布に着目した汎用的な細胞画像のセグメンテーションのためのマルチドメイン学習
- IS1-38:Satayu Parinayok (Univ. of Tokyo), Kazuyo Hirose (Japan Space Systems), Yoko Yamakata (Univ. of Tokyo),Discovering Artisanal and Small-Scale Gold Mining in Satellite Images by Deep Neural Network
- IS1-39:Nicolas Michel, Giovanni Chierchia, Romain Negrel, Jean-François Bercher (Univ. Gustave Eiffel, ESIEE Paris, LIGM), Toshihiko Yamasaki (Univ. of Tokyo),New metrics for analyzing Continual Learners
- IS1-40:向井皇喜, 山崎俊彦 (東大),継続学習における敵対的頑健性の変化
- IS1-41:Kenji Cari Koga, Nakamasa Inoue, Rei Kawakami (Tokyo Institute of Technology),Trajectory Collection with Few-Shot Imitation Learning and Proximal Policy Optimization
- IS1-42:高野寛己, 太田晋一 (宮城県産業技術総合センター), 宮崎智, 大町真一郎 (東北大),不整列データセットを用いた異常検知アルゴリズムの性能検証
- IS1-43:Kaede Shiohara (Univ. of Tokyo), Risa Shinoda (Kyoto Univ.),AnimalTracks-17: A Dataset for Animal Track Recognition
- IS1-44:谷本寛樹, 戴暁艶, 田口賢佑, 謝依珊 (京セラ), 藤吉弘亘 (中部大),カットアンドペーストによるデータ拡張のための複数背景を用いたアルファ情報を含む前景テクスチャの取得
- IS1-45:栗岡保 (東工大), 鈴木哲平 (デンソーITラボ), 川上玲 (東工大), 佐藤育郎 (東工大, デンソーITラボ),Teach the way to deform: 教師モデルが持つ不変性の転移
- IS1-46:山田敏輝, 内田誠一 (九大), 原田翔太 (広島市大),Self Attention機構を用いた画像単位でのデータ拡張の適応的選択
- IS1-47:伊藤天詞, 足立浩規, 平川翼, 山下隆義, 藤吉弘亘 (中部大),画像分類タスクにおける損失関数と注視領域の傾向調査
- IS1-48:Kosuke Mizufune, Shunsuke Tanaka, Toshihide Yukitake, Tatsushi Matsubayashi (ALBERT),Margin MCC: Chance-Robust Metric for Video Boundary Detection with Allowed Margin
- IS1-49:石井裕大 (早大), 下茂道人 (深田地質研究所), シモセラエドガー (早大),ガウス過程回帰と局所画像特徴量を用いた産業用X線CT画像からの亀裂抽出
- IS1-50:小島和輝, 飯山将晃 (滋賀大),Iterative Inpainting Augmentationによる不十分なアノテーションからのインスタンスセグメンテーション
- IS1-51:杜銀偉, 韓先花 (山口大),Attention機構を用いた皮膚病変画像認識の検討
- IS1-52:武縄瑞基 (東大), 池畑諭 (NII), 相澤清晴 (東大),360°映像の補完ー入力の回転による性能向上
- IS1-53:Daichi Horita (Univ. of Tokyo), Jiaolong Yang, Dong Chen (MSRA), Yuki Koyama (AIST), Kiyoharu Aizawa (Univ. of Tokyo), Nicu Sebe (Univ. of Trento),Large-Hole Image Completion via a Structure-Guided Diffusion Model
- IS1-54:尾上雄紀, 五十川麻理子 (慶大),スキップ接続を活用した軽量かつ高精度なビデオインペインティング手法
- IS1-55:佐藤凌雅, 原川良介, 岩橋政宏 (長岡技科大),多解像度 Echo State Network によるジャーテスト映像予測
- IS1-56:中野雄太 (IMRA EUROPE), 山崎博之, 藤田剛 (アイシン),ミリ波センサのrawデータを入力とするディープニューラルネットワークの実装と車内乗員検知への適用
- IS1-57:大谷豪 (慶大, AIST), 片岡裕雄 (AIST), 青木義満 (慶大),超解像のための視覚及び言語の統合特徴によるPerceptual Lossの改善
- IS1-58:髙橋遼 (豊橋技科大), 井上直人 (サイバーエージェント),Text-to-Image手法を使用した広告画像生成と構図提案
- IS1-59:土井賢治, 西村修平, 岩崎雅二郎 (ヤフー),拡散モデルによる画像内の物体の任意色への変換および類似画像検索への応用
- IS1-60:木幡咲希, シモセラエドガー (早大),順伝播型ニューラルネットワーク によるブラシスタイル変換
- IS1-61:藤田幸平, 田崎豪 (名城大),未知物体から既知物体への姿勢を維持した画像変換によるzero-shot姿勢推定
- IS1-62:土屋舜太郎, 遠藤健 (日立),認識損失を考慮した夜間における走行路セグメンテーションの高精度化
- IS1-63:小坂拓也 (立命館大), 孔祥博 (富山県立大), 嶋田知泰 (立命館大), 西川広記 (阪大), 冨山宏之 (立命館大),自律飛行ドローンのための深度推定の高速化
- IS1-64:Fanglu Xie, Motohiro Takagi, Hitoshi Seshimo, Yushi Aono (NTT),Refining Line Art from Disentangled Aesthetic Features with Diffusion Models
- IS1-65:増井建斗, 野村将寛, 大谷まゆ (CyberAgent), 中山英樹 (東大),潜在拡散モデルを用いた追加訓練無し画像スタイル変換
- IS1-66:阿部楓也, 岩井翔真, 宮崎智, 大町真一郎 (東北大),生成画像を利用した少数データくずし字認識に関する検討
- IS1-67:泉幸太, 柳井啓司 (電通大),CLIPと微分可能レンダラーを用いたフォントスタイル変換
- IS1-68:青草月子, 劉家慶 (立命館大), Yu Wang (一橋大), 加藤ジェーン (立命館大),Stable Diffusionのファインチューニングによる質感に特化したメイクアップ転送
- IS1-69:Yoshitaka Nozaki, Kenichiro Fukushi, Kosuke Nishihara, Kentaro Nakahara (NEC),TADA: Temporal Alignment Data Augmentation for Skeleton-Based Human Activity Recognition
- IS1-70:川西康友 (理研, 名大, KDDI), 村瀬洋 (名大, KDDI), 西村仁志, 内藤整 (KDDI),姿勢の時間変化パターンを考慮した超低解像度画像系列中の人物姿勢推定
- IS1-71:尾崎匠, 我那覇航, 井上路子, 西山正志 (鳥取大),歩行者間の会話の盛衰認識における複数グループ対応の検討
- IS1-72:Nan Wu, Hiroshi Kera, Kazuhiko Kawamoto (Chiba Univ.),Zero Shot Action Recognition with ChatGPT-based Instruction
- IS1-73:Ryo Fujii, Ryo Hachiuma, Hideo Saito (Keio Univ.),Robust Crowd Density Forecasting by VideoMAE
- IS1-74:Xinpeng Liu, Hiroaki Santo (Osaka Univ.), Yosuke Toda (Phytometrics, Nagoya Univ.), Fumio Okura (Osaka Univ.),TreeFormer: Hard-constrained Image-to-graph Generation
- IS1-75:高三和己, 飯山将晃 (滋賀大),弱教師付きキーポイント検出による漁場推定
- IS1-76:神谷聡 (名城大), 角山貴昭, 楠美明弘 (OIST), 堀田一弘 (名城大),フレーム補間を用いた二段階追跡によるたんぱく質分子の多物体追跡
- IS1-77:阿部勇太, 入山太嗣, 小室孝 (埼玉大), 島崎航平, 石井抱 (広島大),ミラー駆動パンチルトカメラを用いた高速視線制御による多人数遠近距離手指骨格検出
- IS1-78:長野紘士朗, 佐藤文彬, 八馬遼, 関井大気 (コニカミノルタ),視覚言語事前学習と推論で共通のDNNを用いる一般化Few-Shot物体検出
- IS1-79:植木一也 (明星大), 鈴木裕真, 宅島寛貴, 堀隆之 (ソフトバンク),ChatGPTを利用したクエリ拡張による映像検索精度の向上
- IS1-80:Phueaksri Itthisak (Nagoya Univ., RIKEN), Marc A. Kastner (Kyoto Univ.), Yasutomo Kawanishi (RIKEN, Nagoya Univ.), Takahiro Komamizu, Ichiro Ide (Nagoya Univ.),Image Collection Scene Graph Summarization Enhancing Relation Predictor with External Knowledge
- IS1-81:Rintaro Yanagi (Hokkaido Univ.), Yamato Okamoto, Shuhei Yokoo (LINE), Shin’ichi Satoh (NII),A comprehensive analysis of video copy detection in short video-sharing service
- IS1-82:王良羽, 山肩洋子, 相澤清晴 (東大),食事評価のための食事画像認識を目的としたユーザ生成型レシピからの自動データセット構築
- IS1-83:Takumi Nishiyasu (Univ. of Tokyo), Wataru Shimoda (CyberAgent), Yoichi Sato (Univ. of Tokyo),Multiple Conditioned Image Cropping
- IS1-84:Mang Ling Ada Fok (Univ. of Tokyo, Technical Univ. of Munich), Ling Xiao, Toshihiko Yamasaki (Univ. of Tokyo),Video Summarization Based on Masked Autoencoder
- IS1-85:Da Huo (Nagoya Univ.), Marc A. Kastner (Kyoto Univ.), Takatsugu Hirayama (Univ. of Human Environments), Takahiro Komamizu, Ichiro Ide (Nagoya Univ.),Leverage Semantic Alignment of Object Relations for Image Captioning
- IS1-86:Yanjun Sun (Keio Univ., AIST), Yue Qiu (AIST), Yoshimitsu Aoki (Keio Univ.), Hirokatsu Kataoka (AIST),Boosting Outdoor Vision-and-Language Navigation with On-the-route Objects
- IS1-87:松平茅隼 (名大), カストナーマークアウレル (京大), 駒水孝裕 (名大), 平山高嗣 (人間環境大, 名大), 道満恵介 (中京大, 名大), 井手一郎 (名大),類音語の連想性を考慮した未知語の発音に対する画像生成
- IS1-88:仲直航, 佐藤真一 (NII, 東大),データベースの特性を考慮したバランスの良い画像検索の実現に向けて
- IS1-89:原口大地, 内田誠一 (九大),対照学習における注意とその応用
- IS1-90:Jan Zdenek, Wataru Shimoda, Kota Yamaguchi (CyberAgent),Can We Erase Japanese Text from Images Without Japanese Training Data?
- IS1-91:木下純哉, 宮崎智, 大町真一郎 (東北大),パーツプロトタイプを用いたくずし字認識に関する検討
- IS1-92:折橋翔太, 山﨑善啓, 内田美尋, 高島瑛彦, 東羅翔太郎, 増村亮 (NTT),文字検出と物体検出の統合事前学習を用いた情景文字検出
- IS1-93:Keita Takeda, Tomoya Sakai (Nagasaki Univ.), Eiji Mitate (Kanazawa Medical Univ.), Shunta Matsumoto (Nagasaki Univ.),Unsupervised cell segmentation and background removal for debiasing cytological diagnosis
- IS1-94:菊地遼 (名工大), 岩堀祐之 (中部大), 舟橋健司 (名工大), 小笠原尚高, 春日井邦夫 (愛知医大),内視鏡フード画像からのポリープの形状及び大きさの推定
- IS1-95:竹崎隼平, Weizhi Shi (九大), Gantugs Atarsaikhan (ヘルシンキ大), 内田誠一 (九大),事前学習済みU-Netによる画像処理パイプライン
- IS1-96:片山豊 (阪公大医学部附属病院), 上田健太郎 (デンソー), 日浦慎作 (兵庫県立大),生成系人工知能による超解像を適用した医用画像の評価方法
- IS1-97:池田直輝, 遠里由佳子 (立命館大),線虫胚の顕微鏡画像の異常検知におけるメモリ構造を持つ自己符号化器の有効性
- IS1-98:国方慶悟, 菓子野天音, 山本洋太, 谷口行信 (東京理科大), 曽我部陽光, 松本鮎美, 北原正樹 (NTT), 入江豪 (東京理科大),ハイパースペクトル画像を用いた個人認証
- IS1-99:吉野弘毅, 中嶋一斗, 安正鎬 (九大), 岩下友美 (NASA, Caltech), 倉爪亮 (九大),歩容特徴に基づく歩行者画像の新規生成を用いた歩容認証
- IS1-100:七海友康, 川本一彦, 計良宥志 (千葉大),画像の微小な劣化の検出
- IS1-101:中田道寛, 斎藤奨 (早大), 中野鐵兵 (知能フレームワーク研究所), 小川哲司 (早大),映像監視に基づく意思決定支援のための事前学習モデルの構築法と繁殖牛の分娩検知への応用
- IS1-102:新井達紀, 櫻田国治 (慶大), 五十川麻理子 (慶大, JSTさきがけ), 杉本麻樹 (慶大),合成データセットを用いた赤外線画像による3次元人物姿勢推定
- IS1-103:江角翼, 武村紀子 (九工大),座圧情報を用いたグループ活動における話者推定
- IS1-104:望田康太, 中野鐵兵 (早大), 藤江真也 (千葉工大), 若林麻里, 佐藤朝美 (横浜市大), 小川哲司 (早大),重症心身障害児を対象とした顔表情に基づく感情状態推定のための事前学習モデルに関する検討
- IS1-105:新田恭寛 (慶大), 五十川麻理子 (慶大, JSTさきがけ), 米谷竜, 杉本麻樹 (慶大),街中シーン内のオブジェクト重要度順序推定に基づく音声情報提示システム
- IS1-106:Shoko Sawada (Univ. of Tokyo), Tomoyuki Suzuki (CyberAgent), Masashi Toyoda (Univ. of Tokyo),Enhancing Advertising Image Refinement with Visual Explanations of Effectiveness Prediction
- IS1-107:Xueting Wang, Mayu Otani (CyberAgent),Weakly-supervised Component Recommendation with Content Rating Enhancement
- IS1-108:山西博雅, 山崎俊彦 (東大),Heterogeneous Graphによる観光地の人気解析
- IS1-109:楊心明, 奈良亮耶, 王良羽, 山肩洋子, 相澤清晴 (東大),食材推定モデルを用いた食事記録アプリケーションの開発
- IS1-110:木場竣哉 (立命館大), 吉頴 (名大), 劉家慶 (立命館大), 王彧 (一橋大), 加藤ジェーン (立命館大),野球中継における投球動作の詳細認識
- IS1-111:Yunyi Guan, Asako Kanezaki (Tokyo Institute of Technology),Active Object Recognition in Discrete and Continuous View Settings
- IS1-112:鈴木貴大, 橋本学 (中京大),人とロボットの身体性ギャップを考慮したティーチング作業簡素化のための組み立て動作転移手法
- IS1-113:鈴木達哉, 劉国慶, 宮澤一之, 内田祐介 (GO),画像特徴量の類似度を用いた道路標識の変化検知
- IS1-114:村上大斗, 陳嘉雷, 出口大輔 (名大), 平山高嗣 (人間環境大, 名大), 川西康友 (理研, 名大), 村瀬洋 (名大),交通シーンにおける歩行者の注視対象物推定の検討
- IS1-115:笹口翔伍, Bisser Raytchev, 川口幹祐 (広島大), 植木義治, 小林謙太, 和田好隆, 上村匠, 佐藤圭峰 (マツダ), 檜垣徹, 金田和文 (広島大),Transformerを用いたマルチタスク学習による流体解析の時間効率改善に関する研究
- IS1-116:中直斗, Bisser Raytchev, 笹口翔伍 (広島大), 上村匠, 川口幹祐, 佐藤圭峰, 植木義治, 小林謙太, 和田好隆 (マツダ), 檜垣徹, 金田和文 (広島大),機械学習を用いた冷媒回路のサロゲートモデル化に関する研究
14:30-16:30 DS: デモ (会場:展示ホール)
- DS-1:寺内健人, 山本耕平, 柳井啓司 (電通大),CalorieCam360: 全方位カメラによる複数人同時食事カロリー量推定システム
- DS-2:石山塁, 倪浩 (NEC), フリューランペル, ウヴレボトンスタイン (Retrams),タグ不要で多種複数を自動認識する 手術器具個体識別システムの開発と実用化
- DS-3:Yusuke Sekikawa, Jun Nagata (Denso IT Lab.),Tangentially Elongated Gaussian Belief Propagation for Event-based Optical Flow Estimation in Realtime
- DS-4:出口裕之, 池田航, 堀涼介, 五十川麻理子, 斎藤英雄 (慶大),EventPointMesh in Realtime:イベント情報のみを用いた三次元人物姿勢および形状のリアルタイム推定
- DS-5:川合諒 (NEC), 大見一樹 (名工大), 吉田登, 劉健全 (NEC),画像認識に関する簡易コンサルティングシステム
- DS-6:柳凜太郎 (北大), 橋本敦史(オムロンサイニックエックス), 千葉直也 (東北大, オムロンサイニックエックス), 牛久祥孝 (オムロンサイニックエックス),特徴折込みモデルを導入した三次元点群マッチングに基づく 密な姿勢推定システム
- DS-7:坂口翼, 濱口竜平, 大西正輝, 櫻田健 (AIST),HMNetを用いたイベントデータからのリアルタイム画像認識
- DS-8:龍宮寺嵩士, 北野和哉, ビンダーヨハネス, 石山塁, 舩冨卓哉, 向川康博 (NAIST),レーザスペックル認証による類似物体の個体識別
- DS-9:武中広大, 岩口尭史 (九大), 久保尋之 (千葉大), 川崎洋 (九大),裸眼立体視ディスプレイとヘッドトラッキングを用いた自由視点立体映像の個別提示による共同作業システム
- DS-10:Shengzhou Yi (Univ. of Tokyo), Junichiro Matsugami (Rubato), Takuya Yamamoto, Yukiyoshi Katsumizu (P&I Information Engineering), Toshihiko Yamasaki (Univ. of Tokyo),Online Presentation Skill Training Systems Using Multi-Modal Neural Networks
14:30-16:30 EX: 企業展示 (会場:展示ホール)
- EX-P1:コニカミノルタ株式会社,
- EX-P2:日本電気株式会社,
- EX-P3:株式会社サイバーエージェント,
- EX-P4:株式会社Rist,
- EX-P5:華為技術日本株式会社,
- EX-P6:オムロン株式会社,
- EX-G1:株式会社デンソーアイティーラボラトリ,
- EX-G2:GO株式会社,
- EX-G3:株式会社センスタイムジャパン,
- EX-G4:株式会社AIメディカルサービス,
- EX-G5:株式会社アラヤ,
- EX-G6:Sansan株式会社,
- EX-G7:株式会社HPCテック,
- EX-G8:三菱重工業株式会社,
- EX-G9:株式会社 ZOZO NEXT,
- EX-G10:株式会社日立製作所,
- EX-G11:LINE株式会社,
- EX-G12:日本電信電話 株式会社,
- EX-G13:エムスリー株式会社,
- EX-G14:株式会社講談社,
- EX-G15:SambaNova Systems Japan合同会社,
- EX-G16:株式会社東芝,
- EX-G17:株式会社アイシン,
- EX-G18:株式会社本田技術研究所,
- EX-G19:株式会社IMAGICA GROUP,
- EX-G20:アジア航測株式会社,
- EX-G21:ダイキン工業株式会社,
- EX-G22:株式会社tiwaki,
- EX-G24:株式会社コンピュータマインド,
- EX-G25:株式会社アールティ,
- EX-G26:クラスター株式会社,
- EX-G27:株式会社MIXI,
- EX-G28:グーグル合同会社,
- EX-S1:ケイエルブイ株式会社,
- EX-S2:ヤフー株式会社,
- EX-S3:株式会社ジーデップ・アドバンス,
16:30-17:00 移動・休憩
17:00-18:00 PT1: 特別講演1 (会場:大ホール,中ホール(中継)) (座長:槇原靖)
18:30-21:00 企業企画 華為技術日本株式会社 (会場:52+53+54会議室)
7月27日(木)
9:00-10:30 OS3A: オーラル3A(ネットワーク構造) (会場:大ホール) (座長:松川徹,横田達也)
- OS3A-L1:Toshihiro Ota (CyberAgent), Masato Taki (Rikkyo Univ.),iMixer: invertible, implicit, and iterative MLP-Mixer from modern Hopfield networks
- OS3A-L2:Yusuke Sekikawa, Shingo Yashima (Denso IT Lab.),SAS: Structured Activation Sparsification
- OS3A-L3:後藤優太 (東京理科大), 柴田剛志, 木村昭悟 (NTT), 入江豪 (東京理科大),特徴の変換に基づく選択的忘却
- OS3A-L4:東大樹, 松井勇佑 (東大),CLIPにおけるタイポグラフィック攻撃を防ぐためのPrefix学習
- OS3A-L5:小濱大和, 箕浦大晃, 平川翼, 山下隆義, 藤吉弘亘 (中部大),事前学習を考慮したシングルショット非構造枝刈り手法の提案
- OS3A-L6:Yuiko Sakuma, Masato Ishii, Takuya Narihira (Sony Group),DetOFA: Efficient Training of Once-for-All Networks for Object Detection via Path Filter
9:00-10:30 OS3B: オーラル3B(言語と画像・マルチモーダル) (会場:中ホール) (座長:橋本敦史,小川貴弘)
- OS3B-L1:舘野将寿, 八木拓真, 古田諒佑, 佐藤洋一 (東大),大規模言語モデルを用いた学習カテゴリの自動決定による映像からのオープン語彙物体状態認識
- OS3B-L2:Hiromichi Kamata, Yuiko Sakuma, Akio Hayakawa, Masato Ishii, Takuya Narihira (Sony Group),Instruct 3D-to-3D: Text Instruction Guided 3D-to-3D conversion
- OS3B-L3:Antonio Tejero-de-Pablos (CyberAgent),Dissecting multimodal learning via regularized masking of multimodal features
- OS3B-S1:Yuto Watanabe, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Text-guided Image Manipulation Tolerant to Real-world Image
- OS3B-S2:筒川和樹, 佐藤文彬, 八馬遼, 関井大気 (コニカミノルタ),TextGuide: 説明文に基づくゼロショット長期間行動解析システム
- OS3B-S3:Zhuofan Sun, Daichi Horita (Univ. of Tokyo), Satoshi Ikehata (NII), Kiyoharu Aizawa (Univ. of Tokyo),Text-to-3D Generation Enhanced by the Integration of Signed Distance Fields
- OS3B-S4:Jiafeng Mao (Univ. of Tokyo), Xueting Wang (CyberAgent),Training-Free Location-Aware Text-to-Image Synthesis
- OS3B-S5:平尾努 (NTT), 小林尚輝, 上垣外英剛, 奥村学 (東工大), 木村昭悟 (NTT),動画談話構造解析: ベースライン解析器とその分析
- OS3B-S6:李相明, 品川政太朗, 中村哲 (NAIST),CLIPにおけるテキストの構文情報理解による画像識別能力の向上
- OS3B-S7:入澤優太 (青学大, AIST), 伊東聖矢 (青学大), 櫻田健, 濱口竜平, 大西正輝 (AIST), 大原剛三 (青学大),視点を考慮した3D Dense Captioning
10:30-10:45 休憩
10:45-11:30 OS4A: オーラル4A(事前学習モデル) (会場:大ホール) (座長:横田達也,内海ゆづ子)
- OS4A-L1:山田亮佑 (AIST, 筑波大), 原健翔, 片岡裕雄, 牧原昂志 (AIST), 井上中順, 横田理央 (AIST, 東工大), 佐藤雄隆 (AIST, 筑波大),Formula-Supervised Visual-Geometric Pre-training
- OS4A-L2:篠田理沙 (AIST, 京大), 速水亮 (AIST, 東京電機大), 中嶋航大 (AIST), 井上中順, 横田理央 (東工大), 片岡裕雄 (AIST),数式ドリブン教師あり学習によるセマンティックセグメンテーション
- OS4A-L3:田所龍 (東北大,AIST ), 山田亮佑 (AIST, 筑波大), 片岡裕雄 (AIST),Formula-driven Supervised Learning for 3D Medical Image Segmentation
10:45-11:30 OS4B: オーラル4B(行動認識) (会場:中ホール) (座長:川上玲,大倉史生)
- OS4B-L1:佐藤禎哉 (東大), 高木基宏 (NTT), 古田諒佑, 菅野裕介, 佐藤洋一 (東大),一人称視点映像を対象としたfew-shotアクティビティ認識
- OS4B-L2:佐藤文彬, 八馬遼, 関井大気 (コニカミノルタ),動画単位の行動ラベルを用いた弱教師あり事前学習に基づくゼロショット時空間行動検出
- OS4B-S1:陳俊文, 王瀛成, 柳井啓司 (電通大),人物・物体・動作デコーダの分離によるHOI検出
- OS4B-S2:吉田周平, 寺尾真, 柴田剛志 (NEC),Object-Aware Feature Extraction for Video Action Recognition
11:30-13:10 昼休憩
11:45-12:55 企業企画 日本電気株式会社 (会場:52+53+54会議室)
13:10-14:10 PT2: 特別講演2 (会場:大ホール,中ホール(中継)) (座長:槇原靖)
14:10-14:25 休憩
14:25-15:30 OS5A: オーラル5A(ヒューマンセンシング・植物/文書画像処理) (会場:大ホール) (座長:小川貴弘,内海ゆづ子)
- OS5A-L1:Yingrui Ye, Yuya Moroto, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Zero-shot Visual Sentiment Prediction with Cross-domain Sentiments Using Knowledge Distillation
- OS5A-L2:堀涼介 (慶大), 五十川麻理子 (慶大, JSTさきがけ), 三上弾 (工学院大), 斎藤英雄 (慶大),イベント情報のみを用いた三次元人物姿勢および形状推定
- OS5A-S1:三好遼, 秋月秀一 (中京大), 飛谷謙介 (長崎県立大), 長田典子 (関西学院大), 橋本学 (中京大),基本感情の関係性に基づいた表情認識のためのHierarchical Classification Transformer
- OS5A-S2:Kotaro Amaya (Keio Univ.), Mariko Isogawa (Keio Univ., JST Presto),Adaptive and Robust mmWave-Based 3D Human Mesh Estimation for Diverse Poses
- OS5A-S3:大武一平, 北野和哉, 櫛田貴弘, 藤村友貴 (NAIST), 前島謙宣 (オー・エル・エム・デジタル, IMAGICAGROUP), 久保尋之 (千葉大), 舩冨卓哉, 向川康博 (NAIST),イベントカメラを用いた人物姿勢推定結果の更新によるレイテンシ補償と精度向上
- OS5A-S4:宮川稜平, 山藤浩明, 大倉史生, 松下康之 (阪大),微分可能レンダリングを用いた実植物の構造トラッキング
- OS5A-S5:中鶴慧, 内田誠一 (九大),機械学習によるカーニング
14:25-15:30 OS5B: オーラル5B(ニューラルシーン表現・カメラ校正) (会場:中ホール) (座長:佐川立昌,櫻田健)
- OS5B-L1:周舒意, 謝舒翔 (東大, AIST), 石川涼一 (東大), 櫻田健, 大西正輝 (AIST), 大石岳史 (東大),ニューラル場を用いたLiDARカメラシステムのセンサ融合
- OS5B-L2:中野学 (NEC),カメラの相互射影による2視点幾何のセルフキャリブレーション
- OS5B-S1:石川裕也, 高橋桂太, 水野良哉, 佐藤千幸, 都竹千尋, 藤井俊彰 (名大),単一の符号化画像からの連続的な光線空間の再構成
- OS5B-S2:藤村友貴, 櫛田貴弘, 舩冨卓哉, 向川康博 (NAIST),NLOS-NeuS: 非視線方向撮影におけるニューラル陰関数表面
- OS5B-S3:西川由馬, 坂上文彦, 佐藤淳 (名工大),光線の歪みを考慮したNeRFによる空間構造とシーン形状の同時3次元復元
- OS5B-S4:金岡大樹 (九工大, 理研), 薗頭元春 (理研), 田向権 (九工大), 川西康友 (理研),ManifoldNeRF: 視点変化に伴う特徴ベクトルの連続変化に着目したFew-shot NeRF
- OS5B-S5:Nobuhiko Wakai, Satoshi Sato, Yasunori Ishii (Panasonic Holdings), Takayoshi Yamashita (Chubu Univ.),Deep Single Image Camera Calibration by Heatmap Regression to Recover Fisheye Images Under Manhattan World Assumption Without Ambiguity
15:30-16:00 移動・休憩
16:00-18:00 IS2: インタラクティブ2 (会場:展示ホール)
- OS1A-S6:塩原楓 (東大), 楊興超, 武富貴史 (サイバーエージェント),顔交換のためのアイデンティティエンコーダの再考
- OS3A-L1:Toshihiro Ota (CyberAgent), Masato Taki (Rikkyo Univ.),iMixer: invertible, implicit, and iterative MLP-Mixer from modern Hopfield networks
- OS3A-L2:Yusuke Sekikawa, Shingo Yashima (Denso IT Lab.),SAS: Structured Activation Sparsification
- OS3A-L3:後藤優太 (東京理科大), 柴田剛志, 木村昭悟 (NTT), 入江豪 (東京理科大),特徴の変換に基づく選択的忘却
- OS3A-L4:東大樹, 松井勇佑 (東大),CLIPにおけるタイポグラフィック攻撃を防ぐためのPrefix学習
- OS3A-L5:小濱大和, 箕浦大晃, 平川翼, 山下隆義, 藤吉弘亘 (中部大),事前学習を考慮したシングルショット非構造枝刈り手法の提案
- OS3A-L6:Yuiko Sakuma, Masato Ishii, Takuya Narihira (Sony Group),DetOFA: Efficient Training of Once-for-All Networks for Object Detection via Path Filter
- OS3B-L1:舘野将寿, 八木拓真, 古田諒佑, 佐藤洋一 (東大),大規模言語モデルを用いた学習カテゴリの自動決定による映像からのオープン語彙物体状態認識
- OS3B-L2:Hiromichi Kamata, Yuiko Sakuma, Akio Hayakawa, Masato Ishii, Takuya Narihira (Sony Group),Instruct 3D-to-3D: Text Instruction Guided 3D-to-3D conversion
- OS3B-L3:Antonio Tejero-de-Pablos (CyberAgent),Dissecting multimodal learning via regularized masking of multimodal features
- OS3B-S1:Yuto Watanabe, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Text-guided Image Manipulation Tolerant to Real-world Image
- OS3B-S3:Zhuofan Sun, Daichi Horita (Univ. of Tokyo), Satoshi Ikehata (NII), Kiyoharu Aizawa (Univ. of Tokyo),Text-to-3D Generation Enhanced by the Integration of Signed Distance Fields
- OS3B-S4:Jiafeng Mao (Univ. of Tokyo), Xueting Wang (CyberAgent),Training-Free Location-Aware Text-to-Image Synthesis
- OS3B-S5:平尾努 (NTT), 小林尚輝, 上垣外英剛, 奥村学 (東工大), 木村昭悟 (NTT),動画談話構造解析: ベースライン解析器とその分析
- OS3B-S6:李相明, 品川政太朗, 中村哲 (NAIST),CLIPにおけるテキストの構文情報理解による画像識別能力の向上
- OS3B-S7:入澤優太 (青学大, AIST), 伊東聖矢 (青学大), 櫻田健, 濱口竜平, 大西正輝 (AIST), 大原剛三 (青学大),視点を考慮した3D Dense Captioning
- OS4A-L1:山田亮佑 (AIST, 筑波大), 原健翔, 片岡裕雄, 牧原昂志 (AIST), 井上中順, 横田理央 (AIST, 東工大), 佐藤雄隆 (AIST, 筑波大),Formula-Supervised Visual-Geometric Pre-training
- OS4A-L2:篠田理沙 (AIST, 京大), 速水亮 (AIST, 東京電機大), 中嶋航大 (AIST), 井上中順, 横田理央 (東工大), 片岡裕雄 (AIST),数式ドリブン教師あり学習によるセマンティックセグメンテーション
- OS4A-L3:田所龍 (東北大,AIST ), 山田亮佑 (AIST, 筑波大), 片岡裕雄 (AIST),Formula-driven Supervised Learning for 3D Medical Image Segmentation
- OS4B-L1:佐藤禎哉 (東大), 高木基宏 (NTT), 古田諒佑, 菅野裕介, 佐藤洋一 (東大),一人称視点映像を対象としたfew-shotアクティビティ認識
- OS4B-L2:佐藤文彬, 八馬遼, 関井大気 (コニカミノルタ),動画単位の行動ラベルを用いた弱教師あり事前学習に基づくゼロショット時空間行動検出
- OS4B-S1:陳俊文, 王瀛成, 柳井啓司 (電通大),人物・物体・動作デコーダの分離によるHOI検出
- OS4B-S2:吉田周平, 寺尾真, 柴田剛志 (NEC),Object-Aware Feature Extraction for Video Action Recognition
- OS5A-L1:Yingrui Ye, Yuya Moroto, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Zero-shot Visual Sentiment Prediction with Cross-domain Sentiments Using Knowledge Distillation
- OS5A-L2:堀涼介 (慶大), 五十川麻理子 (慶大, JSTさきがけ), 三上弾 (工学院大), 斎藤英雄 (慶大),イベント情報のみを用いた三次元人物姿勢および形状推定
- OS5A-S1:三好遼, 秋月秀一 (中京大), 飛谷謙介 (長崎県立大), 長田典子 (関西学院大), 橋本学 (中京大),基本感情の関係性に基づいた表情認識のためのHierarchical Classification Transformer
- OS5A-S2:Kotaro Amaya (Keio Univ.), Mariko Isogawa (Keio Univ., JST Presto),Adaptive and Robust mmWave-Based 3D Human Mesh Estimation for Diverse Poses
- OS5A-S3:大武一平, 北野和哉, 櫛田貴弘, 藤村友貴 (NAIST), 前島謙宣 (オー・エル・エム・デジタル, IMAGICAGROUP), 久保尋之 (千葉大), 舩冨卓哉, 向川康博 (NAIST),イベントカメラを用いた人物姿勢推定結果の更新によるレイテンシ補償と精度向上
- OS5A-S4:宮川稜平, 山藤浩明, 大倉史生, 松下康之 (阪大),微分可能レンダリングを用いた実植物の構造トラッキング
- OS5A-S5:中鶴慧, 内田誠一 (九大),機械学習によるカーニング
- OS5B-L1:周舒意, 謝舒翔 (東大, AIST), 石川涼一 (東大), 櫻田健, 大西正輝 (AIST), 大石岳史 (東大),ニューラル場を用いたLiDARカメラシステムのセンサ融合
- OS5B-L2:中野学 (NEC),カメラの相互射影による2視点幾何のセルフキャリブレーション
- OS5B-S1:石川裕也, 高橋桂太, 水野良哉, 佐藤千幸, 都竹千尋, 藤井俊彰 (名大),単一の符号化画像からの連続的な光線空間の再構成
- OS5B-S2:藤村友貴, 櫛田貴弘, 舩冨卓哉, 向川康博 (NAIST),NLOS-NeuS: 非視線方向撮影におけるニューラル陰関数表面
- OS5B-S3:西川由馬, 坂上文彦, 佐藤淳 (名工大),光線の歪みを考慮したNeRFによる空間構造とシーン形状の同時3次元復元
- OS5B-S4:金岡大樹 (九工大, 理研), 薗頭元春 (理研), 田向権 (九工大), 川西康友 (理研),ManifoldNeRF: 視点変化に伴う特徴ベクトルの連続変化に着目したFew-shot NeRF
- OS5B-S5:Nobuhiko Wakai, Satoshi Sato, Yasunori Ishii (Panasonic Holdings), Takayoshi Yamashita (Chubu Univ.),Deep Single Image Camera Calibration by Heatmap Regression to Recover Fisheye Images Under Manhattan World Assumption Without Ambiguity
- IS2-1:佐古田峻輔, 中村友哉, 槇原靖, 八木康史 (阪大),時空間符号化照明と再構成ネットワークの同時最適化による人物超解像シルエットイメージング
- IS2-2:金澤樹希 (筑波大), 青砥隆仁 (Optech Innovation), 髙谷剛志 (筑波大),光の時間遅れと偏光状態を用いた材質分類の検討
- IS2-3:Andreu Girbau, Shin’ichi Satoh (NII),Online Event Downsampling
- IS2-4:城彰彦, 浦西友樹, 長原一 (阪大),微分可能レンダリングを用いた透明物体の自由視点画像生成
- IS2-5:Shogo Sato, Yasuhiro Yao, Taiga Yoshida, Takuhiro Kaneko, Shingo Ando, Jun Shimamura (NTT),Unsupervised Intrinsic Image Decomposition with LiDAR Intensity
- IS2-6:倉田夏菜, 渡邊真由子, 谷田隆一, 島村潤 (NTT),サーモグラフィとRGB画像の統合処理に向けたNeRFの応用
- IS2-7:河村健太郎, 小篠裕子 (東京電機大),ハイパースペクトル画像を用いた手の画素毎分類
- IS2-8:渡邊純平, 山藤浩明, 大倉史生, 松下康之 (阪大),樹木位置を用いた地上・空中撮影点群間の位置合わせ
- IS2-9:野首侑作, 坂上文彦, 佐藤淳 (名工大),手描き画像に含まれる曖昧性と3次元形状の同時復元
- IS2-10:山口峻矢, 藤原航平, 酒井智弥 (長崎大),教師なし学習による低ランク性・スパース性をもつオプティカルフロー場の推定
- IS2-11:Yuchen Che (ALBERT, 東工大), 古川遼, 山内隆太郎, 松林達史 (ALBERT),複数動作姿勢点群データを用いた関節付き物体パーツモビリティ認識モデルの教師無し学習
- IS2-12:古川遼, 山内隆太郎, 松林達史 (ALBERT),点群系列からの表面再構成と点の対応付けへの剛体変換同変性の導入
- IS2-13:Hong Liu (NII), Yongqing Sun (Nihon Univ.), Shin’ichi Satoh (NII, Univ. of Tokyo),Rethinking Robust 3D Recognition via Multi-view Test-Time Adaptation
- IS2-14:三浦康平, 岩井大輔, 佐藤宏介 (阪大),複数のRGB-Dカメラと熱カメラを用いた非剛体に対する手作業の三次元復元
- IS2-15:Itsuki Ueda (Univ. of Tsukuba), Naoya Chiba (Waseda Univ.), Hirokatsu Kataoka (AIST), Hiroaki Aizawa (Hiroshima Univ.), Itaru Kitahara (Univ. of Tsukuba),Fast Learning of Reciprocally Constrained Fields for Density and Distance
- IS2-16:大隣嵩 (東大), 池畑諭 (NII, 東工大, 東大), 相澤清晴 (東大),セグメンテーションマスクを利用した動画からの静的なNeRF表現の学習
- IS2-17:齊藤啓介, 坂上文彦, 佐藤淳 (名工大),未知物体上の映り込みを用いた隠れた物体の3次元復元
- IS2-18:今津良祐, 都竹千尋, 高橋桂太, 藤井俊彰 (名大),光線空間を単眼画像と付加情報によって表現する学習ベースの圧縮符号化
- IS2-19:井手優希, 川原僚, 岡部孝弘 (九工大),半透明物体の法線とPSFの同時推定
- IS2-20:永田耕太郎, 堀田一弘 (名城大),オンライン継続学習のための学習可能ベクトルを用いた対照学習
- IS2-21:奥田萌莉, 石澤秀紘, 大島裕明 (兵庫県立大),画像認識によるウキクサ科植物の表面積と総枚数の推定
- IS2-22:鈴木雅司, 平川翼, 山下隆義, 藤吉弘亘 (中部大),Attention Branch Transformer:Top-down Attention機構を用いた頑健なViTの提案
- IS2-23:田上鈴奈, 小林大起, 秋月秀一, 橋本学 (中京大),周辺物との相互関係に基づく最適な色と明るさ情報の組み合わせによる高信頼画像マッチング
- IS2-24:Soichiro Kumano (Univ. of Tokyo), Hiroshi Kera (Chiba Univ.), Toshihiko Yamasaki (Univ. of Tokyo),Probabilistic Approach towards Theoretical Understanding for Adversarial Training
- IS2-25:Ken Eto, Yuko Ozasa (Tokyo Denki Univ.),Behavior of out-of-distribution data in image classification with deep learning
- IS2-26:佐藤篤樹, 松井勇佑 (東大),Fast Partitioned Learned Bloom Filter
- IS2-27:鈴木聡志, 武田翔一郎, 谷田隆一, 坂東幸浩 (NTT), 庄野逸 (電通大),Neural Activation Pattern Matching 損失を用いた歪み付き画像分類
- IS2-28:池川慎一 (アイシン), 齊院龍二 (アイシン, アイシン・ソフトウェア), 澤田好秀 (アイシン),ΣΔ-S3NN: Single-Step Spiking Neural Network based Sigma-Delta Network
- IS2-29:Yu Li (Ritsumeikan Univ.), Yu Wang (Hitotsubashi Univ.), Yanwei Chen, Jien Kato (Ritsumeikan Univ.),Shadow Training with Varied Complexity in Membership Inference Attacks
- IS2-30:Atsuyuki Miyai, Qing Yu (Univ. of Tokyo), Go Irie (Tokyo Univ. of Science), Kiyoharu Aizawa (Univ. of Tokyo),Can Pre-trained Networks Detect Familiar Out-of-Distribution Data?
- IS2-31:Hiroki Nakamura, Masashi Okada (Panasonic Holdings), Tadahiro Taniguchi (Panasonic Holdings, Ritsumeikan Univ.),混合画像の自己教師あり表現学習における特徴量の多値論理合成
- IS2-32:岩根昂平, 鈴木昌人, 高橋智一, 青柳誠司 (関西大), 須戸文夫, 頼光敏幸 (二九精密機械工業),自己組織化マップを用いた微細部品のクラスタリング
- IS2-33:Takashi Horihata, Ryota Higashimoto, Soh Yoshida, Mitsuji Muneyasu (Kansai Univ.),Causal Inference-based Unbiased Pseudo-Labeling for Learning with Noisy Labels
- IS2-34:村田健悟, 伊東聖矢, 大原剛三 (青学大),ClassPrompt: 継続学習へのPrompt Tuningの応用
- IS2-35:奥野智行 (パナソニックホールディングス), Jinze Yu (Beihang Univ.), Jiaming Liu, Xiaobao Wei (Peking Univ.), Haoyi Zhou (Beihang Univ.), 中田洋平 (パナソニックホールディングス), Denis Gudovskiy (Panasonic AI Lab.), Jianxin Li (Beihang Univ.), Kurt Keutzer (Univ. of California, Berkeley), Shanghang Zhang (Peking Univ.),MTTrans: Mean Teacherの枠組みを用いた物体検出Transformer向け教師なしドメイン適応
- IS2-36:杉山海斗, 計良宥志, 川本一彦 (千葉大),教師なしドメイン適応のためのデータセット最適化
- IS2-37:権田祥之介, 坂上文彦, 佐藤淳 (名工大),敵対的学習における複数Discriminatorの学習の安定化
- IS2-38:村瀬卓也, 佐々木一磨, 北岡伸也, 小田桐優理 (ドワンゴ),自己教師あり行動推定に基づくゲームプレイ動画の模倣による強化学習の効率化
- IS2-39:Chi Zhang, Toshihiko Yamasaki (Univ. of Tokyo),BSTM: Blurring-Sharpening Training Models for Collaborative Filtering
- IS2-40:新原慎司, 森稔 (神奈川工科大),画像認識における多次元テンソル表現ラベルの改良及び評価
- IS2-41:藤井駿伍, 足立浩規 (中部大), 小塚和紀, 石井育規 (パナソニック), 平川翼, 山下隆義, 藤吉弘亘 (中部大),特徴量の類似性に基づく混合クラスの選択を導入したデータ拡張
- IS2-42:高瀬朝海 (AIST),データ拡張指標を利用した拡張ポリシーの探索
- IS2-43:澁谷辰吉, 井上中順, 川上玲 (東工大), 佐藤育郎 (東工大, デンソーITラボ),二値重み空間でのBinary Neural Networksの学習
- IS2-44:栗原大翔, 前田英作 (東京電機大),数式駆動型学習によるVision Transformerの事前学習について
- IS2-45:上野詩翔, 山田悠正 (岐阜大), 中塚俊介 (岐阜大, パナソニック), 加藤邦人 (岐阜大),深層能動学習におけるクエリ戦略の有効性調査
- IS2-46:保久良允彦, 吉岡理文, 井上勝文 (阪公大),CPUのキャッシュメモリがCNNの推論速度へ与える影響の調査
- IS2-47:中西慶一, 徳永旭将 (九工大),パッチ画像を用いた半教師あり学習に基づくセグメンテーションフレームワーク
- IS2-48:伊藤光一郎, 三木亮祐, 渡邉裕樹 (日立),Mask2Formerを用いた衛星画像中被災建屋検知に向けたObject query設計と学習時の割り当て制御の検討
- IS2-49:髙間斐斗, 神谷聡, 堀田一弘 (名城大),Word Patchesを用いたTransUNetの精度向上
- IS2-50:中嶋航大 (サイバーエージェント, 筑波大), 菊池康太郎, 岩崎祐貴 (サイバーエージェント),グラフィックデザインの教師ありレイヤー分解
- IS2-51:小杉哲 (東工大), 山崎俊彦 (東大),認識モデルに適応可能な画像補正手法
- IS2-52:Shiho Noda, Koki Tsubota, Kiyoharu Aizawa (Univ. of Tokyo),Deep Image Compression for Machines — Universally Applicable to Pre-trained Classification Models
- IS2-53:依田一希, 川本一彦, 計良宥志 (千葉大),画像破損がある場合の分布外検知精度の検証
- IS2-54:山田偉央, 奥野弘嗣 (阪工大),視細胞応答に基づいた画像符号化が色恒常性アルゴリズムに与える影響
- IS2-55:各務嘉記, 古川陽一, 丸山隆浩, 堀田一弘 (名城大),ShiftIR-GANによる超解像度
- IS2-56:Ryugo Morita, Zhiqiang Zhang, Jinjia Zhou (Hosei Univ.),Background Interpretation-based Foreground Image Synthesis
- IS2-57:黒川幸将, 山脇香菜, Bisser Raytchev, 野村典文, 尾形陽一, 川口幹祐 (広島大), 上村匠 (マツダ), 檜垣徹, 金田和文 (広島大),流体シミュレーションにおける深層学習モデル適用の検討
- IS2-58:兵田憲信, 飯塚里志, 福井和広 (筑波大),Environment MattingにおけるTransformerモデルの提案
- IS2-59:荒川深映, 綱島秀樹 (早大), 堀田大地 (東大), 田中啓太郎, 森島繁生 (早大),パッチ分割による拡散確率モデルのメモリ消費量削減の検討
- IS2-60:安部航太朗, 村田竜輝, 西山正志, 岩井儀雄 (鳥取大),オートエンコーダと整数ウェーブレットを用いた高解像度未来画像予測生成法の検討と評価
- IS2-61:菓子野天音, 国方慶悟, 山本洋太, 入江豪 (東京理科大), 曽我部陽光, 松本鮎美, 北原正樹 (NTT), 谷口行信 (東京理科大),個人識別におけるRGB・ハイパースペクトル画像変換によるデータ拡張の有効性の検証
- IS2-62:福田拓真, 計良宥志, 川本一彦 (千葉大),ソースクラスを考慮した誘導付き逆拡散による画像変換
- IS2-63:岩井翔真, 宮崎智, 大町真一郎 (東北大),GANを使ったマルチレート画像符号化モデルのための学習戦略の検討
- IS2-64:星澤知宙, 入山太嗣, 小室孝 (埼玉大),視点補間ネットワークによる映り込みを伴う金属物体の質感再現
- IS2-65:増田康希, 入山太嗣, 小室孝 (埼玉大),画像スタイル変換を用いた映り込み生成による金属の質感再現
- IS2-66:小谷七海, 金崎朝子 (東工大),注目領域の抽出に基づく全天球画像からの指示物体推定
- IS2-67:福沢匠, 細谷優, 玉木徹 (名工大),キャプション生成を用いたzero-shot動作認識
- IS2-68:グエンチュンタイン (名大), 川西康友 (理研, 名大), 駒水孝裕, 井手一郎 (名大),時間マルチスケール特徴と行動ラベル特徴によるオープンボキャブラリ行動区間認識
- IS2-69:原健翔, 小林三将, 佐藤雄隆 (AIST),Neural Radiance Fieldsによる動画像のカメラ位置固定による人物行動認識への影響の分析
- IS2-70:永井隆昌, 江崎健司, 瀬下仁志 (NTT),マスク映像を用いたContrastive RegressionによるAction Quality Assessment
- IS2-71:Xiangyu Chen, Shin’ichi Satoh (Univ. of Tokyo, NII),Why is Video Relation Detection So Difficult
- IS2-72:Masashi Hatano, Ryo Hachiuma, Hideo Saito (Keio Univ.),Predicting Future Hand Movements with Ego-motion in First-person Video
- IS2-73:宮田優一, 井上勝文, 吉岡理文 (阪公大),Optimal Correction Cost を用いた物体検出における誤検出削減の検討
- IS2-74:本多浩大, 内田祐介 (GO),CLRerNet:LaneIoUによりレーン信頼度スコア学習を改善したレーン検出手法
- IS2-75:薗頭元春 (理研), 飯山将晃 (滋賀大), 川西康友 (理研),Open-setシーングラフ生成のための物体間の関係を考慮した未知物体検出
- IS2-76:中林拓也, 近藤壮真, 斎藤英雄 (慶大),イベントカメラを用いた深層学習によるバレーボール位置検出
- IS2-77:Taku Sasaki, Kazuki Adachi, Shohei Enomoto, Yoshihiro Ikeda (NTT), Adam Walmsley (NTT, Univ. of British Columbia), Shin’ya Yamaguchi (NTT),Re-training-aware Automatic Model Evaluation for Person Re-Identification
- IS2-78:山崎智史, 劉健全 (NEC),長時間映像における人物行動要約のデータセットとその評価
- IS2-79:手嶋仁志 (九大), 中村まい (お茶の水女子大), 和家尚希, 高松淳 (Microsoft), 川崎洋 (九大), 池内克史 (Microsoft),VAEを用いた特徴抽出によるアメリカ北西海岸の 民族舞踊の階層的クラスタリング
- IS2-80:Shiyu Teng, Jiaqing Liu, Shurong Chai (Ritsumeikan Univ.), Tomoko Tateyama (Fujita Health Univ.), Xinyin Huang (Soochow Univ.), Lanfen Lin (Zhejiang Univ.), Yen-Wei Chen (Ritsumeikan Univ.),An Intra- and Inter-Emotion Transformer-based Fusion Model with Homogeneous and Diverse Constraints Using Multi-emotional Audiovisual Features for Depression Detection
- IS2-81:今井海人, 内田奏 (Sansan),Vision-Language Modelによる局所構造を考慮したFew-shot画像品質評価モデル
- IS2-82:水谷航悠, 山﨑俊彦 (東大),Transformerを用いたプレゼンテーションスライドの順序予測
- IS2-83:前田将寿, 深澤樹生, 柴田千尋 (法政大),マルチモーダル感情分析におけるcross-attentionとself-attentionの優位性に関する考察
- IS2-84:濱田裕太, 品川政太朗, 中村哲 (NAIST),テキストからの画像生成の評価指標としてのシーングラフ類似度
- IS2-85:富谷竜一, Tristan Hascoet, 高島遼一, 滝口哲也 (神戸大),CLIPを用いた画像検索におけるファインチューニングのための学習データ収集戦略
- IS2-86:大島遼祐 (早大), 品川政太朗 (NAIST), 綱島秀樹, 馮起, 森島繁生 (早大),Visual Dialogueにおける人間の応答ミス指摘の検討
- IS2-87:三谷勇人 (九大), 木村昭悟 (NTT), 内田誠一 (九大),情景内単語の選択的消去
- IS2-88:藤武将人 (ファーストアカウンティング, FA Research),拡散モデルを用いたシーンテキスト認識
- IS2-89:近藤徹多, 原口大地, 内田誠一 (九大),スタイル特徴は演算可能か?
- IS2-90:近野翼, 二宮高洋, 三浦幹太, 伊藤康一, 檜森紀子, Parmanand Sharma, 中澤徹, 青木孝文 (東北大),1D+2D U-Net を用いた OCT 画像からの網膜層セグメンテーションの検討
- IS2-91:山岡悠, Weng Ian Chan, 瀬尾茂人, 深田宗一朗, 松田秀雄 (阪大),筋組織再生過程の順序尺度評価に向けた時系列ラベルを用いる弱教師有り学習の提案
- IS2-92:坂井凛香, 福島祥之 (室蘭工大), 甲斐千遥 (新潟医療福祉大), 大塚恒博 (大塚ブレストケアクリニック), 二村仁 (コニカミノルタ), 笠井聡 (新潟医療福祉大), 近藤敏志 (室蘭工大),マンモグラムの左右比較手法の検討
- IS2-93:中林雄一 (DeepEyeVision), 近藤佑亮 (DeepEyeVision, 東大),二値分類器ゲートによるカラー眼底像からのNPA予測における偽陽性抑制
- IS2-94:Yuna Kato, Mariko Isogawa (Keio Univ.), Shohei Mori (Graz Univ. of Technology), Hideo Saito, Hiroki Kajita, Yoshifumi Takatsume (Keio Univ.),High-Quality Virtual Single-Viewpoint Surgical Video: Geometric Autocalibration of Multiple Cameras in Surgical Lights
- IS2-95:上田健太郎 (デンソー), 片山豊 (大阪公立大学医学部附属病院),二方向から撮像した放射線画像による三次元容積の推定および点群データへの変換
- IS2-96:Ryo Fujii, Ryo Hachiuma, Hideo Saito (Keio Univ.),Weakly Semi-supervised Tool Detection in Minimally Invasive Surgery Videos
- IS2-97:庄司悠歩, 戸泉貴裕, 伊藤厚史 (NEC),マルチタスク学習とアンサンブル学習を用いた未知の種類に頑健なカラーコンタクトレンズ検知
- IS2-98:城間亮, 早川季寿, 中西慶一, 徳永旭将 (九工大),外部視覚注視機構による深層学習の異常検出能力と注視領域生成方法の関係について
- IS2-99:小林大起, 橋本学 (中京大),透過マスクを用いた実欠陥特徴の転移に基づく異常検知
- IS2-100:Yuya Moroto, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Human Emotion Recognition While Viewing Images Based on Multi-view Variational Recurrent Neural Network
- IS2-101:石井遊哉, 池田浩雄 (NEC),カメラ-骨間角度に基づく正則化を用いた単眼3次元姿勢推定
- IS2-102:Kyohei Kamikawa, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama (Hokkaido Univ.),Feature integration introducing back-projection based on ordering in labels for rating prediction
- IS2-103:永田剛大, 天野敏之 (和歌山大),複数レイヤの同時見かけの制御
- IS2-104:鷹野礼音, 小篠裕子 (東京電機大),選択した雰囲気に合わせた空間デザイン
- IS2-105:冨田雄大, 和田俊和 (和歌山大),全天球カメラを使用した視線方向画像の生成
- IS2-106:原川良介, 岩橋政宏 (長岡技科大),社会的イベントの影響を受けたトレンドクラスタの抽出 —新型コロナウイルスに関するツイートの分析—
- IS2-107:今宿祐希, 山肩洋子, 相澤清晴 (東大),Vision-Language事前学習モデルを用いた日本食画像のゼロショット分類とプロンプトエンジニアリング
- IS2-108:藤原雄太 (立命館大), 孔祥博 (富山県立大), 田中亜実 (立命館大), 西川広記 (阪大), 冨山宏之 (立命館大),卓球のボール追跡によるイン/アウト判定
- IS2-109:合楽慧, 金崎朝子 (東工大),画像の意味的領域分割を用いた強化学習による室内環境探索
- IS2-110:佐藤郎真, 井上中順, 川上玲 (東工大),ロボットによる物体再配置における多変量正規分布を用いた衝突回避
- IS2-111:玄元奏 (立命館大), 飯田啄巳, 小西嘉典 (SenseTime Japan),LanesPose: 骨格推定によるレーン検出
- IS2-112:重中亨介, 孫唯嘉, ロジャナアテェラパト, 米司健一 (デンソー),自動運転に向けた走路・物体認識のためのマルチカメラデータセット構築
- IS2-113:矢橋和也, 藤田幸平, 田崎豪 (名城大),高さの異なる2視点を用いた実環境での姿勢推定精度の向上
- IS2-114:小長井俊介, 阿部直人, 吉田大我, 谷田隆一 (NTT),DNN建物抽出結果の整列化効果検討報告
- IS2-115:ChangSub Yun, HoYoung Kim, YunHa Park (WooKyoung Information Technology),Graph Vision Transformer Model for Child Behaviors Analysis System
16:00-18:00 DS: デモ (会場:展示ホール)
- DS-1:寺内健人, 山本耕平, 柳井啓司 (電通大),CalorieCam360: 全方位カメラによる複数人同時食事カロリー量推定システム
- DS-2:石山塁, 倪浩 (NEC), フリューランペル, ウヴレボトンスタイン (Retrams),タグ不要で多種複数を自動認識する 手術器具個体識別システムの開発と実用化
- DS-3:Yusuke Sekikawa, Jun Nagata (Denso IT Lab.),Tangentially Elongated Gaussian Belief Propagation for Event-based Optical Flow Estimation in Realtime
- DS-4:出口裕之, 池田航, 堀涼介, 五十川麻理子, 斎藤英雄 (慶大),EventPointMesh in Realtime:イベント情報のみを用いた三次元人物姿勢および形状のリアルタイム推定
- DS-5:川合諒 (NEC), 大見一樹 (名工大), 吉田登, 劉健全 (NEC),画像認識に関する簡易コンサルティングシステム
- DS-6:柳凜太郎 (北大), 橋本敦史(オムロンサイニックエックス), 千葉直也 (東北大, オムロンサイニックエックス), 牛久祥孝 (オムロンサイニックエックス),特徴折込みモデルを導入した三次元点群マッチングに基づく 密な姿勢推定システム
- DS-7:坂口翼, 濱口竜平, 大西正輝, 櫻田健 (AIST),HMNetを用いたイベントデータからのリアルタイム画像認識
- DS-8:龍宮寺嵩士, 北野和哉, ビンダーヨハネス, 石山塁, 舩冨卓哉, 向川康博 (NAIST),レーザスペックル認証による類似物体の個体識別
- DS-9:武中広大, 岩口尭史 (九大), 久保尋之 (千葉大), 川崎洋 (九大),裸眼立体視ディスプレイとヘッドトラッキングを用いた自由視点立体映像の個別提示による共同作業システム
- DS-10:Shengzhou Yi (Univ. of Tokyo), Junichiro Matsugami (Rubato), Takuya Yamamoto, Yukiyoshi Katsumizu (P&I Information Engineering), Toshihiko Yamasaki (Univ. of Tokyo),Online Presentation Skill Training Systems Using Multi-Modal Neural Networks
16:00-18:00 EX: 企業展示 (会場:展示ホール)
- EX-P1:コニカミノルタ株式会社,
- EX-P2:日本電気株式会社,
- EX-P3:株式会社サイバーエージェント,
- EX-P4:株式会社Rist,
- EX-P5:華為技術日本株式会社,
- EX-P6:オムロン株式会社,
- EX-G1:株式会社デンソーアイティーラボラトリ,
- EX-G2:GO株式会社,
- EX-G3:株式会社センスタイムジャパン,
- EX-G4:株式会社AIメディカルサービス,
- EX-G5:株式会社アラヤ,
- EX-G6:Sansan株式会社,
- EX-G7:株式会社HPCテック,
- EX-G8:三菱重工業株式会社,
- EX-G9:株式会社 ZOZO NEXT,
- EX-G10:株式会社日立製作所,
- EX-G11:LINE株式会社,
- EX-G12:日本電信電話 株式会社,
- EX-G13:エムスリー株式会社,
- EX-G14:株式会社講談社,
- EX-G15:SambaNova Systems Japan合同会社,
- EX-G16:株式会社東芝,
- EX-G17:株式会社アイシン,
- EX-G18:株式会社本田技術研究所,
- EX-G19:株式会社IMAGICA GROUP,
- EX-G20:アジア航測株式会社,
- EX-G21:ダイキン工業株式会社,
- EX-G22:株式会社tiwaki,
- EX-G24:株式会社コンピュータマインド,
- EX-G25:株式会社アールティ,
- EX-G26:クラスター株式会社,
- EX-G27:株式会社MIXI,
- EX-G28:グーグル合同会社,
- EX-S1:ケイエルブイ株式会社,
- EX-S2:ヤフー株式会社,
- EX-S3:株式会社ジーデップ・アドバンス,
18:00-20:00 交流会 (会場:展示ホール)
- 今回のMIRUではバンケットは開催しませんが,インタラクティブセッション会場で参加者同士の交流を図る時間(交流会)を設けます.対面での交流をお楽しみください.交流会ではコーヒーブレイクのように飲み物と軽食を提供します.
7月28日(金)
9:00-10:00 OS6A: オーラル6A(コンピューテーショナルフォトグラフィ・光学的解析) (会場:大ホール) (座長:久保尋之,田中賢一郎)
- OS6A-L1:日垣輝大, 北野和哉, 櫛田貴弘, 藤村友貴, 舩冨卓哉, 向川康博 (NAIST),1対のウェッジプリズムを用いた屈折型リサージュサンプリングによる光線空間計測
- OS6A-S1:吉村優大, 八谷大岳 (和歌山大),鏡面フローとハイライトに基づく深層特徴による鏡面検出
- OS6A-S2:難波優駿, 韓先花 (山口大),Coupling Spatial and Channel Transformer Networkを用いた単一画像の雨除去
- OS6A-S3:中田健太, 前田涼汰, 日浦慎作 (兵庫県立大),単一光子検出器を用いた表面下散乱のトランジェント偏光イメージング
- OS6A-S4:Jose Reinaldo Cunha Santos A V Silva Neto, Tomoya Nakamura, Yasushi Makihara, Yasushi Yagi (Osaka Univ.),Optimized Radial Mask for Extended Depth-of-Field Lensless Imaging
- OS6A-S5:羽渕柊志, 高橋桂太, 水野良哉, 都竹千尋, 藤井俊彰 (名大), 長原一 (阪大),符号化開口とイベントによる光線空間の高効率撮像
- OS6A-S6:山田悠稀, 川原僚, 岡部孝弘 (九工大),ライトトランスポート獲得のための符号化と復号の同時最適化
- OS6A-S7:中村龍太郎, 松田拓晟, 陳文豪, 田中賢一郎 (立命館大),観測比ペアのプロット座標における射影変換を用いた多波長遠赤外測距
9:00-10:00 OS6B: オーラル6B(データ拡張・ネットワーク軽量化/高速化) (会場:中ホール) (座長:関川雄介,川上玲)
- OS6B-L1:浅海標徳, 松尾信之介, 末廣大貴, 備瀬竜馬(九大),クラス比率学習におけるバッグ単位のデータ拡張
- OS6B-L2:Koji Kamma, Toshikazu Wada (Wakayama Univ.),Pruning with Output Error Minimization for Compressing Deep Neural Networks
- OS6B-S1:Yu Mitsuzumi (NTT), Go Irie (Tokyo Univ. of Science, NTT), Akisato Kimura (NTT), Atsushi Nakazawa (Kyoto Univ.),Phase Randomization: A Data Augmentation for Domain Adaptation in Human Action Recognition
- OS6B-S2:Yinan Yang (Ritsumeikan Univ.), Ying Ji (Nagoya Univ.), Yu Wang (Hitotsubashi Univ.), Jien Kato (Ritsumeikan Univ.),Discriminative Data Matters: Enhancing One-shot Pruning at Initialization to Avoid Layer Collapse
- OS6B-S3:足立浩規, 平川翼, 山下隆義, 藤吉弘亘 (中部大),Adversarial mixup: 敵対的な混合比を用いたmixupによるデータ拡張
- OS6B-S4:近藤良太, 箕浦大晃, 平川翼, 山下隆義, 藤吉弘亘 (中部大),Binary-decomposed Vision Transformer:二値分解によるViTモデルの圧縮と推論の高速化
10:00-10:15 休憩
10:15-11:30 ITA: 招待講演A (会場:大ホール) (座長:松川徹,久保尋之)
- ITA-1:Gaku Nakano (NEC),[ECCV 2022] Solution Space Analysis of Essential Matrix based on Algebraic Error Minimization
- ITA-2:Itsuki Ueda (Tsukuba Univ.), Yoshihiro Fukuhara (Waseda Univ.), Hirokatsu Kataoka (AIST), Hiroaki Aizawa (Hiroshima Univ.), Hidehiko Shishido, Itaru Kitahara (Tsukuba Univ.),[ECCV 2022] Neural Density-Distance Fields
- ITA-3:Tomoki Ichikawa, Yoshiki Fukao, Shohei Nobuhara, Ko Nishino (Kyoto Univ.),[CVPR 2023] Fresnel Microfacet BRDF: Unification of Polari-Radiometric Surface-Body Reflection
- ITA-4:Ryo Kawahara (Kyutech), Meng-Yu Jennifer Kuo (Univ. of Minnesota), Shohei Nobuhara (Kyoto Univ.),[CVPR 2023] Teleidoscopic Imaging System for Microscale 3D Shape Reconstruction
- ITA-5:Satoshi Ikehata (NII),[CVPR 2023] Scalable, Detailed and Mask-Free Universal Photometric Stereo
- ITA-6:Takumi Kobayashi (AIST, Univ. of Tsukuba),[CVPR 2023] Two-way Multi-Label Loss
- ITA-7:Bowen Wang, Liangzhi Li, Yuta Nakashima, Hajime Nagahara (Osaka Univ.),[CVPR 2023] Learning Bottleneck Concepts in Image Classification
- ITA-8:Ryuhei Hamaguchi (AIST), Yasutaka Furukawa (Simon Fraser Univ.), Masaki Onishi, Ken Sakurada (AIST),[CVPR 2023] Hierarchical Neural Memory Network for Low Latency Event Processing
- ITA-9:Sora Takashima (AIST, Tokyo Institute of Technology), Ryo Hayamizu (AIST), Nakamasa Inoue (AIST, Tokyo Institute of Technology), Hirokatsu Kataoka (AIST), Rio Yokota (AIST, Tokyo Institute of Technology),[CVPR 2023] Visual Atoms: Pre-Training Vision Transformers With Sinusoidal Waves
- ITA-10:Kengo Nakata, Youyang Ng, Daisuke Miyashita, Asuka Maki, Yu-Chieh Lin, Jun Deguchi (Kioxia),[ECCV 2022] Revisiting a kNN-based Image Classification System with High-capacity Storage
10:15-11:30 ITB: 招待講演B (会場:中ホール) (座長:大倉史生,金子卓弘)
- ITB-1:Naoto Inoue, Kotaro Kikuchi (CyberAgent), Edgar Simo-Serra (Waseda Univ.), Mayu Otani, Kota Yamaguchi (CyberAgent),[CVPR 2023] LayoutDM: Discrete Diffusion Model for Controllable Layout Generation
- ITB-2:Takehiro Aoshima, Takashi Matsubara (Osaka Univ.),[CVPR 2023] Deep Curvilinear Editing: Commutative and Nonlinear Image Manipulation for Pretrained Deep Generative Model
- ITB-3:Kazusato Oko (Univ. of Tokyo, AIP RIKEN), Shunta Akiyama (Univ. of Tokyo), Taiji Suzuki (Univ. of Tokyo, AIP RIKEN),[ICML 2023] Diffusion Models are Minimax Optimal Distribution Estimators
- ITB-4:Yu Takagi, Shinji Nishimoto (Osaka Univ., NICT),[CVPR 2023] High-resolution image reconstruction with latent diffusion models from human brain activity
- ITB-5:Mayu Otani, Riku Togashi, Yu Sawai, Ryosuke Ishigami (CyberAgent), Yuta Nakashima (Osaka Univ.), Esa Rahtu (Tampere Univ.), Janne Heikkilä (Univ. of Oulu), Shin’ichi Satoh (CyberAgent),[CVPR 2023] Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation
- ITB-6:Fumiaki Sato, Ryo Hachiuma, Taiki Sekii (Konica Minolta),[CVPR 2023] Prompt-Guided Zero-Shot Anomaly Action Recognition using Pretrained Deep Skeleton Features
- ITB-7:Yusuke Yoshiyasu (AIST),[CVPR 2023] Deformable Mesh Transformer for 3D Human Mesh Recovery
- ITB-8:Yuto Shibata, Yutaka Kawashima (Keio Univ.), Mariko Isogawa (Keio Univ., JST Presto), Go Irie (Tokyo Univ. of Science), Akisato Kimura (NTT), Yoshimitsu Aoki (Keio Univ.),[CVPR 2023] Listening Human Behavior: 3D Human Pose Estimation With Acoustic Signals
- ITB-9:Yuki Kawana (Univ. of Tokyo), Yusuke Mukuta, Tatsuya Harada (Univ. of Tokyo, RIKEN),[ECCV 2022] Unsupervised Pose-Aware Part Decomposition for Man-made Articulated Objects
- ITB-10:Takehiko Ohkawa (Univ. of Tokyo, Carnegie Mellon Univ.), Yu-Jhe Li, Qichen Fu (Carnegie Mellon Univ.), Ryosuke Furuta (Univ. of Tokyo), Kris M. Kitani (Carnegie Mellon Univ.), Yoichi Sato (Univ. of Tokyo),[ECCV 2022] Domain Adaptive Hand Keypoint and Pixel Localization in the Wild
- ITB-11:Pablo Cervantes (Tokyo Institute of Technology), Yusuke Sekikawa (Denso IT Lab.), Ikuro Sato (Tokyo Institute of Technology, Denso IT Lab.), Koichi Shinoda (Tokyo Institute of Technology),[ECCV 2022] Implicit Neural Representations for Variable Length Human Motion Generation
11:30-13:00 昼休憩
13:00-15:00 IS3: インタラクティブ3 (会場:展示ホール)
- OS3B-S2:筒川和樹, 佐藤文彬, 八馬遼, 関井大気 (コニカミノルタ),TextGuide: 説明文に基づくゼロショット長期間行動解析システム
- OS6A-L1:日垣輝大, 北野和哉, 櫛田貴弘, 藤村友貴, 舩冨卓哉, 向川康博 (NAIST),1対のウェッジプリズムを用いた屈折型リサージュサンプリングによる光線空間計測
- OS6A-S1:吉村優大, 八谷大岳 (和歌山大),鏡面フローとハイライトに基づく深層特徴による鏡面検出
- OS6A-S2:難波優駿, 韓先花 (山口大),Coupling Spatial and Channel Transformer Networkを用いた単一画像の雨除去
- OS6A-S3:中田健太, 前田涼汰, 日浦慎作 (兵庫県立大),単一光子検出器を用いた表面下散乱のトランジェント偏光イメージング
- OS6A-S4:Jose Reinaldo Cunha Santos A V Silva Neto, Tomoya Nakamura, Yasushi Makihara, Yasushi Yagi (Osaka Univ.),Optimized Radial Mask for Extended Depth-of-Field Lensless Imaging
- OS6A-S5:羽渕柊志, 高橋桂太, 水野良哉, 都竹千尋, 藤井俊彰 (名大), 長原一 (阪大),符号化開口とイベントによる光線空間の高効率撮像
- OS6A-S6:山田悠稀, 川原僚, 岡部孝弘 (九工大),ライトトランスポート獲得のための符号化と復号の同時最適化
- OS6A-S7:中村龍太郎, 松田拓晟, 陳文豪, 田中賢一郎 (立命館大),観測比ペアのプロット座標における射影変換を用いた多波長遠赤外測距
- OS6B-L1:浅海標徳, 松尾信之介, 末廣大貴, 備瀬竜馬(九大),クラス比率学習におけるバッグ単位のデータ拡張
- OS6B-L2:Koji Kamma, Toshikazu Wada (Wakayama Univ.),Pruning with Output Error Minimization for Compressing Deep Neural Networks
- OS6B-S1:Yu Mitsuzumi (NTT), Go Irie (Tokyo Univ. of Science, NTT), Akisato Kimura (NTT), Atsushi Nakazawa (Kyoto Univ.),Phase Randomization: A Data Augmentation for Domain Adaptation in Human Action Recognition
- OS6B-S2:Yinan Yang (Ritsumeikan Univ.), Ying Ji (Nagoya Univ.), Yu Wang (Hitotsubashi Univ.), Jien Kato (Ritsumeikan Univ.),Discriminative Data Matters: Enhancing One-shot Pruning at Initialization to Avoid Layer Collapse
- OS6B-S3:足立浩規, 平川翼, 山下隆義, 藤吉弘亘 (中部大),Adversarial mixup: 敵対的な混合比を用いたmixupによるデータ拡張
- OS6B-S4:近藤良太, 箕浦大晃, 平川翼, 山下隆義, 藤吉弘亘 (中部大),Binary-decomposed Vision Transformer:二値分解によるViTモデルの圧縮と推論の高速化
- ITA-1:Gaku Nakano (NEC),Solution Space Analysis of Essential Matrix based on Algebraic Error Minimization
- ITA-2:Itsuki Ueda (Tsukuba Univ.), Yoshihiro Fukuhara (Waseda Univ.), Hirokatsu Kataoka (AIST), Hiroaki Aizawa (Hiroshima Univ.), Hidehiko Shishido, Itaru Kitahara (Tsukuba Univ.),Neural Density-Distance Fields
- ITA-3:Tomoki Ichikawa, Yoshiki Fukao, Shohei Nobuhara, Ko Nishino (Kyoto Univ.),Fresnel Microfacet BRDF: Unification of Polari-Radiometric Surface-Body Reflection
- ITA-4:Ryo Kawahara (Kyutech), Meng-Yu Jennifer Kuo (Univ. of Minnesota), Shohei Nobuhara (Kyoto Univ.),Teleidoscopic Imaging System for Microscale 3D Shape Reconstruction
- ITA-5:Satoshi Ikehata (NII),Scalable, Detailed and Mask-Free Universal Photometric Stereo
- ITA-6:Takumi Kobayashi (AIST, Univ. of Tsukuba),Two-way Multi-Label Loss
- ITA-7:Bowen Wang, Liangzhi Li, Yuta Nakashima, Hajime Nagahara (Osaka Univ.),Learning Bottleneck Concepts in Image Classification
- ITA-8:Ryuhei Hamaguchi (AIST), Yasutaka Furukawa (Simon Fraser Univ.), Masaki Onishi, Ken Sakurada (AIST),Hierarchical Neural Memory Network for Low Latency Event Processing
- ITA-9:Sora Takashima (AIST, Tokyo Institute of Technology), Ryo Hayamizu (AIST), Nakamasa Inoue (AIST, Tokyo Institute of Technology), Hirokatsu Kataoka (AIST), Rio Yokota (AIST, Tokyo Institute of Technology),Visual Atoms: Pre-Training Vision Transformers With Sinusoidal Waves
- ITA-10:Kengo Nakata, Youyang Ng, Daisuke Miyashita, Asuka Maki, Yu-Chieh Lin, Jun Deguchi (Kioxia),Revisiting a kNN-based Image Classification System with High-capacity Storage
- ITB-1:Naoto Inoue, Kotaro Kikuchi (CyberAgent), Edgar Simo-Serra (Waseda Univ.), Mayu Otani, Kota Yamaguchi (CyberAgent),LayoutDM: Discrete Diffusion Model for Controllable Layout Generation
- ITB-2:Takehiro Aoshima, Takashi Matsubara (Osaka Univ.),Deep Curvilinear Editing: Commutative and Nonlinear Image Manipulation for Pretrained Deep Generative Model
- ITB-3:Kazusato Oko (Univ. of Tokyo, AIP RIKEN), Shunta Akiyama (Univ. of Tokyo), Taiji Suzuki (Univ. of Tokyo, AIP RIKEN),Diffusion Models are Minimax Optimal Distribution Estimators
- ITB-4:Yu Takagi, Shinji Nishimoto (Osaka Univ., NICT),High-resolution image reconstruction with latent diffusion models from human brain activity
- ITB-5:Mayu Otani, Riku Togashi, Yu Sawai, Ryosuke Ishigami (CyberAgent), Yuta Nakashima (Osaka Univ.), Esa Rahtu (Tampere Univ.), Janne Heikkilä (Univ. of Oulu), Shin’ichi Satoh (CyberAgent),Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation
- ITB-6:Fumiaki Sato, Ryo Hachiuma, Taiki Sekii (Konica Minolta),Prompt-Guided Zero-Shot Anomaly Action Recognition using Pretrained Deep Skeleton Features
- ITB-7:Yusuke Yoshiyasu (AIST),Deformable Mesh Transformer for 3D Human Mesh Recovery
- ITB-8:Yuto Shibata, Yutaka Kawashima (Keio Univ.), Mariko Isogawa (Keio Univ., JST Presto), Go Irie (Tokyo Univ. of Science), Akisato Kimura (NTT), Yoshimitsu Aoki (Keio Univ.),Listening Human Behavior: 3D Human Pose Estimation With Acoustic Signals
- ITB-9:Yuki Kawana (Univ. of Tokyo), Yusuke Mukuta, Tatsuya Harada (Univ. of Tokyo, RIKEN),Unsupervised Pose-Aware Part Decomposition for Man-made Articulated Objects
- ITB-10:Takehiko Ohkawa (Univ. of Tokyo, Carnegie Mellon Univ.), Yu-Jhe Li, Qichen Fu (Carnegie Mellon Univ.), Ryosuke Furuta (Univ. of Tokyo), Kris M. Kitani (Carnegie Mellon Univ.), Yoichi Sato (Univ. of Tokyo),Domain Adaptive Hand Keypoint and Pixel Localization in the Wild
- ITB-11:Pablo Cervantes (Tokyo Institute of Technology), Yusuke Sekikawa (Denso IT Lab.), Ikuro Sato (Tokyo Institute of Technology, Denso IT Lab.), Koichi Shinoda (Tokyo Institute of Technology),Implicit Neural Representations for Variable Length Human Motion Generation
- IS3-1:山﨑啓太, 髙谷剛志 (筑波大), 青砥隆仁 (Optech Innovation),時間相関を用いた双対画像の生成
- IS3-2:清原孝行, 八子基樹, 山岡義和, 細川誓, 平澤拓, 石川篤 (パナソニックホールディングス),圧縮センシングを用いた高感度ハイパースペクトルカメラの開発
- IS3-3:岩口尭史, 川崎洋 (九大),近接任意光源によるDNNを用いた照度差ステレオによる法線推定
- IS3-4:牧田泰介, 河野裕之 (三菱電機),厚み制御可能な投影型ライトカーテンセンサ
- IS3-5:石井将太, 山藤浩明, 大倉史生, 松下康之 (阪大),微分可能レンダリングによる実物体のBRDF推定
- IS3-6:小野能輝, 坂上文彦, 佐藤淳 (名工大),確率的NeRFによる光線追跡を利用した散乱媒体内の3次元形状復元
- IS3-7:Nana Shirakashi, Yuko Ozasa (Tokyo Denki Univ.),Classifying Hidden Object by Domain Adaptation
- IS3-8:佐藤智, 安木俊介, 八子基樹, 石川篤, 登一生 (パナソニックホールディングス),圧縮ハイパースペクトルカメラにおける マスクパターンの検討
- IS3-9:邵乾瀚, 渡辺義浩 (東工大),変形量分散を用いたグラフ調整による非剛体3次元トラッキングの高速化
- IS3-10:遠藤健, 的野春樹 (日立), 北原格 (筑波大),対象領域外の深度情報を利用した単眼カメラによる深度推定
- IS3-11:蛭田雄也, 謝淳, 宍戸英彦, 北原格 (筑波大),全方位カメラと球面鏡で構成された反射屈折撮像系における3次元推定手法
- IS3-12:伊藤慎太郎, 三浦幹太, 伊藤康一, 青木孝文 (東北大),多視点ステレオのためのNeRF を用いたデプスマップ推定の高精度化
- IS3-13:辻真彦, 松元崇裕, 吉田大我, 千明裕 (NTT),カメラと3D-LiDARを活用した画像による自己位置推定手法の提案
- IS3-14:仵小軍, 谷田隆一, 島村潤 (NTT),大規模3D点群データの階層的構造解析
- IS3-15:髙橋響熙, 上田樹, 北原格 (筑波大),距離場と密度場を互恵的に制約するニューラル場表現NeDDFを用いた単眼Visual SLAM
- IS3-16:大川快 (東工大), 櫻田健 (AIST), 横田理央 (東工大),単眼カメラを用いたリアルタイムな3次元マップの変化検出を目的とした密なバンドル調整
- IS3-17:Mizuki Tabata, Kana Kurata, Junichiro Tamamatsu (NTT),Shape-Net: Room Layout Estimation from Panoramic Images Robust to Occlusion using Knowledge Distillation with 3D Shapes
- IS3-18:松元崇裕, 千明裕, 望月崇由 (NTT),高密度な色付き点群の欠損補完手法と点群彩色DNNの学習方法に関する比較検討
- IS3-19:尾崎一総, 坂上文彦, 佐藤淳 (名工大),非同期カメラの相互投影を利用した自己装着型モーションキャプチャシステム
- IS3-20:佐藤和仁, 山口周悟, 武田司, 森島繁生 (早大),オブジェクトモーションブラー除去のための変形可能なNeRF
- IS3-21:古川諒一, 堀田一弘 (名城大),Enhancing Ensemble Learning Networks
- IS3-22:内田美尋 (NTT), 櫻井真平 (豊橋技科大), 鈴木聡志, 増村亮 (NTT),共変量シフトにロバストなOpen-set Recognition
- IS3-23:住安宏介, 川本一彦, 計良宥志 (千葉大),ゲーム理論の相互作用値を用いた貢献度の高い特徴の特定
- IS3-24:寺内怜央 (東工大), 佐藤育郎 (東工大, デンソーITラボ), 吉橋亮太 (東工大), 池畑諭 (東工大, NII), 加太将弘, 川上玲 (東工大),大規模事前学習済みニューラルネットワークの意味的階層構造の分析
- IS3-25:熊谷香織, 高木基宏, 瀬下仁志, 青野裕司 (NTT),行動主の知識を活用した一人称視線推定手法の検討
- IS3-26:髙橋秀弥 (東京電機大, AIST), 井上中順, 横田理央 (東工大), 片岡裕雄 (AIST), 前田英作 (東京電機大),学習過程における形状・テクスチャ偏重度の推移と事前学習データセットとの関係について
- IS3-27:内田誠一 (九大), 加葉田雄太郎 (長崎大),多目的最適化問題の一意解のための特異点論応用(第二報)
- IS3-28:武田翔一郎, 赤木康紀, 丸茂直貴, 丹羽健太 (NTT),巡回対称性を持つ最適輸送問題
- IS3-29:日比野祐樹, 川本一彦, 計良宥志 (千葉大),深層モデルの部分線形接続性
- IS3-30:加古遼太郎, 松井勇佑 (東大),TransformerにおけるSelf-attention機構のTensor-train分解
- IS3-31:岩垣渚, 岡本直樹, 藤井駿伍, 平川翼, 山下隆義, 藤吉弘亘 (中部大),SimSiamにおけるデータ拡張の効果とmixupの導入による向上
- IS3-32:鈴木藍雅 (大成建設),テクスチャ解析と教師なし学習に基づく一様壁面上の異常検知
- IS3-33:真野嵩大, 神谷聡, 堀田一弘 (名城大),未来方向と過去方向のオプティカルフローを用いた半教師あり学習によるセマンティックセグメンテーション
- IS3-34:吉田舜, 山崎俊彦 (東大),Pretext Taskを用いたMasked Image Modelingの拡張
- IS3-35:Qing Yu (Univ. of Tokyo), Go Irie (Tokyo Univ. of Science), Kiyoharu Aizawa (Univ. of Tokyo),Accelerating Open-Set Domain Adaptation by Visual-Language Foundation Models
- IS3-36:原田翔太 (広島市大), 備瀬竜馬 (九大), 田中聖人 (京都第二赤十字病院), 内田誠一 (九大),クラスの順序関係を利用した半教師付きドメイン適応
- IS3-37:中村譲, 石井育規, 丸山悠樹 (パナソニックホールディングス), 山下隆義 (中部大),ドメイン間の物体領域合成による少量データ向けドメイン適応
- IS3-38:Yuting Lin, Shinichiro Sogo (Kokusai Kogyo),Single Domain Generalization in Semantic Segmentation with Transformer Encoder
- IS3-39:秋山慧斗 (東北大), 徳井翔梧, 徳本晋, 中川尊雄 (富士通),LRP法を用いて最適化する重みを限局した敵対的学習
- IS3-40:前島匠亨 (立命館大), 孔祥博 (富山県立大), 嶋田知泰 (立命館大), 西川広記 (阪大), 冨山宏之 (立命館大),強化学習を用いたドローンの経路計画の最適化
- IS3-41:Satomi Tanaka (Ricoh), Hiroshi Kera, Norimichi Tsumura (Chiba Univ.),Active Evaluation System: Generating a Uniform Perceptual Space using Active learning
- IS3-42:古谷優樹, 齊藤剛史 (九工大), 土屋慶子, 中村京太, 佐藤仁, 安部猛 (横浜市大),効率的な頭部姿勢推定用顔画像データセットの構築
- IS3-43:守脇幸佑, 岩崎幸生, 石原賢太, 井下哲夫 (NEC),OrderAugment: 映像中の動き情報に基づいた異常作業認識のためのデータ拡張手法
- IS3-44:大平都雲, 西口敏司 (阪工大), 豊浦正広 (山梨大),眼底写真に含まれるボケの検出
- IS3-45:森川元晴 (東京電機大), 太田龍之介 (東京電機大, 日立情報通信エンジニアリング), 前田英作 (東京電機大),工業製品の異常検知における数式駆動型学習の有効性について
- IS3-46:平川優伎, 斎藤侑輝 (ZOZO RESEARCH),着用者の体型を考慮したファッションコーディネート推薦
- IS3-47:岡本夏旺, 品川政太朗, 中村哲 (NAIST),クラスラベルを仮定しない画像集合の多様性評価
- IS3-48:鈴木智之, 山口光太 (サイバーエージェント),モーションピクチャのレイヤー分解
- IS3-49:日色紀貴, 田崎豪 (名城大),相互損失による選択的インスタンスセグメンテーション
- IS3-50:藤井春樹, 小野広夢, 堀田一弘 (名城大),Adaptive Resolution Selection Moduleを用いたセマンティックセグメンテーション
- IS3-51:佐々木孝輔, 堀田一弘 (名城大),セマンティックセグメンテーションにおけるAxial-Attentionによる自己知識蒸留
- IS3-52:武小萌, 孫泳青, 木村昭悟 (NTT),Comparametric Equationによる深層画像強調
- IS3-53:青木政勝, 阿部直人, 小長井俊介, 谷田隆一 (NTT),空中写真から抽出した地物形状の補正
- IS3-54:葉青, 井上光平 (九大),クラス間の誤差拡散法に基づく画像のパステルカラー化
- IS3-55:Ling Xiao (Univ. of Tokyo), Xiaofeng Zhang (Univ. of Chinese Academy of Sciences), Toshihiko Yamasaki (Univ. of Tokyo),Improved Fine-grained Fashion Retrieval with Contrastive Learning
- IS3-56:伊藤瑠海 (千葉大), Supatta Viriyavisuthisakul (Panyapiwat Institute of Management), 川本一彦, 計良宥志 (千葉大),変分オートエンコーダによる超解像データセット生成
- IS3-57:Supatta Viriyavisuthisakul (JAIST), Parinya Sanguansat (Panyapiwat Institute of Management), Toshihiko Yamasaki (Univ. of Tokyo),Subjective Evaluation of Super-Resolution Image Reconstructed by Trainable Regularization
- IS3-58:Weng Ian Chan, Xu Cao, Hiroaki Santo, Fumio Okura (Osaka Univ.),Fine-grained Facial Image Manipulation via Latent Space Decomposition
- IS3-59:田仲百音, 山藤浩明, 大倉史生, 松下康之 (阪大),フォトグラメトリ3Dモデルのテクスチャスタイル変換
- IS3-60:Yuantian Huang, Satoshi Iizuka, Kazuhiro Fukui (Univ. of Tsukuba),Diffusion-based Semantic Image Synthesis from Sparse Layouts
- IS3-61:勝又海 (東大, 理研), Duc Minh Vo (東大), 原田達也 (東大, 理研), 中山英樹 (東大),暗黙的な変形場を用いた変形可能な3D敵対的生成ネットワーク
- IS3-62:Takahiro Shirakawa, Seiichi Uchida (Kyushu Univ.),Ambigram Generation and Ambigramability
- IS3-63:Daiki Kimura, Tatsuya Ishikawa, Masanori Mitsugi, Yasunori Kitakoshi, Takahiro Tanaka, Naomi Simumba (IBM), Kentaro Tanaka, Hiroaki Wakabayashi, Masato Sampei (Space Shift), Michiaki Tatsubori (IBM),Winning a Competition of Satellite Image Analysis
- IS3-64:高橋紅葉 (県立広島大), 陳金輝 (和歌山大), 肖業貴 (県立広島大),StyleGAN2によるアニメの顔画像の生成
- IS3-65:安達一生, 栗山繁 (豊橋技科大),拡散モデルを用いた構図不変なテキストベースの実画像変換
- IS3-66:住野奏, 満上育久 (広島市大), 佐川立昌 (AIST),顔ランドマーク点の移動指定による表情編集
- IS3-67:大峠仁輝, 原口大地 (九大), 下田和, 山口光太 (サイバーエージェント), 内田誠一 (九大),アウトライン推定を用いた情景内文字編集へ向けて
- IS3-68:Tsunehiko Tanaka, Edgar Simo-Serra (Waseda Univ.),Leveraging Object Detectors for Online Action Detection
- IS3-69:塩田宰, 高木基宏, 熊谷香織, 瀬下仁志, 青野裕司 (NTT),手-物体の接触と物体状態を捉えた一人称映像行動認識
- IS3-70:森卓, 小野信和, 川﨑寛也 (味の素), 数藤恭子 (東邦大),調理器具ラベルと手関節点座標を用いた調理行動認識
- IS3-71:Yuchi Ishikawa, Masayoshi Kondo, Hirokatsu Kataoka (LINE),Video and Model Encryption for Privacy-Preserving Action Recognition
- IS3-72:藤田倫弘, 川西康友 (理研),マルチスケールな周波数領域で段階的生成を行う姿勢予測手法の提案
- IS3-73:石田汐音, 数藤恭子 (東邦大),SketchRNNを用いた時系列手描きテストパターンの分類
- IS3-74:Jiafeng Mao, Qing Yu (Univ. of Tokyo), Go Irie (Tokyo Univ. of Science), Kiyoharu Aizawa (Univ. of Tokyo),Noise-Avoidance Sampling for Annotation Missing Object Detection
- IS3-75:山内俊典 (日立ハイテク),Spatial Sensitive Grad-CAM++: 勾配の重みづけ平均考慮による物体検出モデルに対する視覚的説明手法の改良
- IS3-76:髙橋友紀子, 松尾弘法, 鄭澤, 高椋佐和 (アイシン),合成画像のスタイル転送ペアリングによる分布外シーン向け物体検出
- IS3-77:辻栄翔, 竹長慎太朗 (筑波大, AIST), 大西正輝 (AIST),物体検出におけるドメインシフトを軽減するデータ拡張
- IS3-78:リュウテイイ (名大, 理研), 川西康友 (理研, 名大), 駒水孝裕, 井手一郎 (名大),検出対象領域の絞込みによる広角映像中の鳥追跡
- IS3-79:吉田登 (NEC), Yi Kun (京大), トウテイテイ, 劉健全 (NEC),不確実性に対応する属性推薦を用いた人物画像検索
- IS3-80:武藤良, 植木一也 (明星大), 鈴木裕真, 宅島寛貴, 堀隆之 (ソフトバンク),検索クエリ文の冗長性の排除による映像検索の改善
- IS3-81:Qianru Qiu, Xueting Wang (CyberAgent),Text-Aware Color Palette Recommendation for Vector Graphic Document
- IS3-82:Ayaka Ideno (Univ. of Tokyo), Takuhiro Kaneko (NTT), Tatsuya Harada (Univ. of Tokyo),Frame-Level Event Representation Learning for Semantic-Level Generation and Editing of Motion
- IS3-83:熊谷はるか (東大), 山木良輔 (ProPlace, 立命館大), 長沼大樹 (ProPlace, モントリオール大, Mila),物語のコンテキスト情報を用いた拡散モデル
- IS3-84:Bolin Zhang (Hunan Univ., Nagoya Univ.), Haruya Kyutoku (Aichi Univ. of Technology, Nagoya Univ.), Keisuke Doman (Chukyo Univ., Nagoya Univ.), Takahiro Komamizu (Nagoya Univ.), Chao Yang, Bin Jiang (Hunan Univ.), Ichiro Ide (Nagoya Univ.),Unified Transformer with Fine-grained Contrastive Learning for Cross-modal Recipe Retrieval
- IS3-85:Yamato Okamoto (LINE), Haruto Toyonaga (Doshisha Univ.), Hirokatsu Kataoka, Yoshihisa Ijiri (LINE),Constructing Image-Text Pair Dataset from Books
- IS3-86:南里卓也, 陳放歌, 三田康博, 西山乘 (日産自動車),CLIPを用いた自動車デザイン印象評価の可能性検証
- IS3-87:北岸毅一, Sai Htaung Kham, 柳圭佑, 後藤亮介 (ZOZO RESEARCH),ファッショントレンドの検出と予測: SNS 投稿データのクラスタリングと時系列分析
- IS3-88:Kevin Xu, Yusuke Sugano (Univ. of Tokyo),Adapting Vision Language Models to Image Regression Tasks
- IS3-89:片岡蓮太郎 (九大), 木村昭悟 (NTT), 内田誠一 (九大),敵対的攻撃に頑健な文字のデザインをめざして
- IS3-90:竹長慎太朗 (筑波大), 内田奏 (Sansan),確信度に基づいた自己修正機構を持つ高速な文字認識モデル
- IS3-91:ピョンケイジ (九大), Xiaomeng Wu (NTT), 内田誠一 (九大),Regional Diffusionによる手書き数式認識結果の事後補正
- IS3-92:橋口裕貴, 若森万悠, 大図奈美 (神戸情報大学院大), 高原俊介 (兵庫県立加古川医療センター整形外科), 野田光昭 (西病院整形外科), 大寺亮 (神戸情報大学院大),機械学習を用いた骨盤骨折X線画像におけるTAE要否判定の検討
- IS3-93:外尾航季, 三森隆広 (早大), 松井啓隆 (国立がん研究センター, 熊本大), 浜田道昭 (早大, AIST),血球画像を対象とした解釈性のある異常検知モデルの開発
- IS3-94:山根健寛 (九大), 津下到, 齊藤晋 (京大), 備瀬竜馬 (九大),医用画像セグメンテーションにおけるPU Learningを用いた疑似ラベル選択
- IS3-95:重安勇輝 (九大), 原田翔太 (広島市大), 荒木健吾 (九大), 吉澤明彦, 寺田和弘 (京大), 備瀬竜馬 (九大),病理画像セグメンテーションにおける腫瘍の長径を用いた弱教師付き半教師学習の提案
- IS3-96:古川栞, 武村紀子 (九工大),変分オートエンコーダを用いた歩容映像の個人特徴を考慮した疾患推定
- IS3-97:安正鎬, 中嶋一斗, 吉野弘毅 (九大), 岩下友美 (NASA, JPL), 倉爪亮 (九大),複数投影視点の適応的学習に基づく3D LiDARを用いた歩容認証
- IS3-98:野村侑平 (和歌山県工業技術センター, 和歌山大), 八谷大岳 (和歌山大),周波数依存の画像再構成誤差に基づく極小欠陥検出
- IS3-99:柏本雄士朗, 山地雄土 (東芝), 高柳佳幸 (東芝ライテック),カメラ付き照明器具と映像解析AI技術による 製造現場での業務改善
- IS3-100:朝枝彩夏, 武村紀子 (九工大),顔画像における個人特徴の分離による個人差を考慮したユーザ状態推定
- IS3-101:内田滋穂里, 柳川由紀子, 小泉昌之, 中嶋宏 (オムロン),カフ圧脈波画像によるDeformable Convolutionを用いた血圧計測
- IS3-102:米谷竜, 馬場惇 (サイバーエージェント),フロアプラン情報を手掛かりとした最適化に基づくNeural Inertial Localization
- IS3-103:疋田善地, 山口周悟, 岩本尚也, 森島繁生 (早大),ブレンドシェイプを用いて個人の表情や個性を反映した3D顔モデルのリターゲティング
- IS3-104:神田亜門 (東京電機大), 内川惠二 (神奈川工科大), 小篠裕子 (東京電機大),オプティマルカラー仮説に基づく色知覚に個人差が生じる画像生成
- IS3-105:荒金大清, 齊藤剛史 (九工大),画像ベースモデルと特徴点ベースモデルを統合した日本語文章読唇
- IS3-106:前田亮真, 山﨑俊彦 (東大),マルチモーダル深層学習を用いたインフルエンサーの人気度予測
- IS3-107:濱田大聖, 金子直史, 中島克人 (東京電機大),野球のバッティング上達支援のためのスイング解析
- IS3-108:楊明哲 (東大, オムロンサイニックエックス), 橋本敦史, Jiaxin Ma (オムロンサイニックエックス), 本田秀仁 (追手門学院大), 田中一敏 (オムロンサイニックエックス),卓球映像からの打球の攻守推定
- IS3-109:近藤暖, 金崎朝子 (東工大),動的複数音源定位手法を用いたマルチゴール視聴覚ナビゲーション
- IS3-110:茶屋道暢 (住友重機械搬送システム), 原孝介 (住友重機械工業), 酒井幹夫 (東大),粉体シミュレーションからの掘削予測モデルの学習と軌道生成への適用
- IS3-111:影山雄太 (阪大), 小西嘉典 (センスタイムジャパン),3次元レーン検出のための合成データ活用に向けたドメイン適応手法の検討
- IS3-112:久徳遙矢 (愛知工科大, 豊田工大), 秋田時彦, 三田誠一 (豊田工大),車載カメラ用途における各種局所画像特徴の精度評価
- IS3-113:Nagma S. Khan, Jiro Abe, Gaku Nakano, Kazumine Ogura (NEC),Accurate 3D Map Update Using Geometry-guided Change Detection for RGB-D Images
- IS3-114:石山遼 (九大), 鷹見竣希, 重中秀介 (筑波大, AIST), 大西正輝 (AIST),大規模マルチエージェントシミュレーションにおけるデータ同化高速化手法の検討
- IS3-115:加納直行, 久徳遙矢 (愛知工科大), 道満恵介 (中京大), 川西康友 (理研),しいたけの自動選別実現に向けた深度画像に基づくサイズ分類器の構築
- IS3-116:竹崎大起, 李天鎬 (岡山理科大), 星名豊 (住友電工),自己教師あり学習を用いたケーブル内の極小素線検出